
Inbound webhooks look simple until they hit real operations: retries, timeouts, out-of-order delivery and CRM rate limits. If you connect Stripe, Shopify or your product app directly to your CRM you will eventually see duplicate records, missing updates and hard-to-debug automation failures. This article shows a practical gateway pattern for API development and integration that turns unreliable inbound webhooks into reliable CRM writes with idempotency, controlled retries, dead-letter handling and observability.
Quick summary:
- Accept and verify webhooks fast then queue them so providers stop retrying while you process safely.
- Make every downstream action idempotent using stable keys and upserts so duplicates become harmless.
- Use retry with backoff plus a dead-letter queue so failures are recoverable without manual data cleanup.
- Instrument logs and metrics around queue age, error categories and CRM rate limits so ops can trust automation during spikes.
Quick start
- Stand up a minimal gateway endpoint that only verifies signature then stores a raw event and returns HTTP 200 within a few seconds.
- Generate an idempotency key per event and persist a dedupe record before any CRM write.
- Push the verified event into a queue and process it in a worker that performs CRM upserts by external ID.
- Implement retry with exponential backoff for transient CRM failures and route poison events to a dead-letter queue.
- Add dashboards and alerts for DLQ depth, queue lag and CRM error rates then test replay safely.
A reliable webhook-to-CRM layer acknowledges webhooks quickly, verifies and validates payloads, stores each event durably then processes it asynchronously with idempotent upserts. Retries should use backoff and stop at a defined limit then move the event to a dead-letter queue for triage and replay. With basic logs and metrics around queue lag, error types and dedupe hits you prevent duplicates, avoid dropped writes and make failures operationally predictable.
Why webhook-to-CRM delivery fails in production
This boundary is where even strong teams get burned because providers behave differently and your CRM is usually the least forgiving downstream system.
- Providers retry aggressively. Shopify expects a response within about 5 seconds and can retry multiple times over hours if you do not respond successfully. If your handler does CRM writes inline it will timeout during spikes and trigger more retries.
- Delivery order is not guaranteed. You may receive an update before a create. Treating events as sequential commands creates race conditions and bad CRM state.
- Downstream APIs rate-limit and throttle. CRMs commonly respond with 429s under load. If you retry incorrectly you create a thundering herd that amplifies the outage.
- Payloads evolve. New fields appear, types change and optional fields become required. Without schema validation you get silent partial updates or worker crashes.
A common failure pattern we see is a single endpoint that verifies the webhook and then immediately creates or updates CRM objects. It works in development and fails during the first promotion, billing spike or CRM incident. The fix is architectural: separate receipt from side effects. If you want a broader overview of how this same approach supports automation across teams, see How Custom API Integration Powers Automation, Workflow Efficiency, and Scalable Growth.
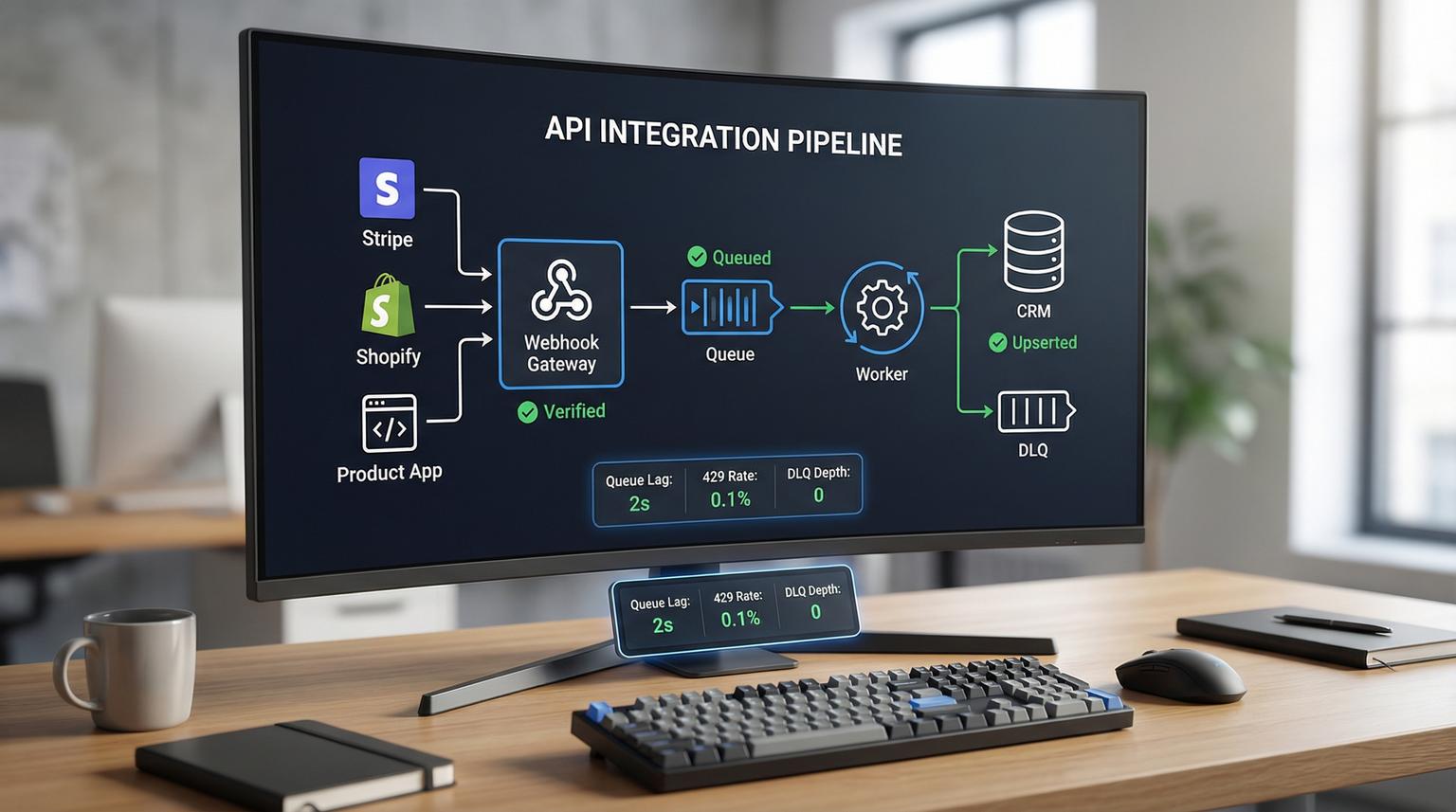
The gateway architecture you can standardize across SaaS apps
Think of the gateway as an internal integration layer that converts any provider webhook into a consistent internal event format and processing workflow.
Components
- Gateway endpoint: receives the webhook, verifies signature using the raw body, performs lightweight validation and returns a fast 2xx.
- Validation and normalization: parses into a canonical internal event with stable fields like provider, event_type, occurred_at, external_object_id and idempotency_key.
- Event store: persists the verified event payload and metadata for replay and audits. This can be a database table or an object store plus an index.
- Queue: buffers and smooths spikes. It is the contract between inbound webhooks and downstream processing.
- Worker: consumes queued events, enforces idempotency then calls the CRM adapter.
- CRM adapter: one module per CRM that handles upsert strategy, mapping and rate-limit handling.
- Dead-letter queue (DLQ): receives events that exceed retry limits or fail with non-retriable errors.
- Observability: structured logs plus metrics and alerts that cover the full path from receipt to CRM commit.

This pattern is consistent with provider guidance like Shopify recommending queuing to meet response time expectations and with real-world Stripe webhook reliability lessons such as expecting duplicates and out-of-order delivery. For reference, Shopify highlights the fast response requirement and raw-body signature verification in their webhook delivery docs.
Data contract and event record you should store
Durable storage is what makes retries and replays safe. Store the raw payload and also a normalized envelope that the worker can process without provider-specific parsing each time.
Minimal internal event envelope
{
"event_id": "evt_01J...",
"provider": "stripe",
"provider_event_id": "evt_1P...",
"event_type": "invoice.paid",
"occurred_at": "2026-04-08T12:34:56Z",
"received_at": "2026-04-08T12:34:57Z",
"idempotency_key": "stripe:evt_1P...",
"external_object": {
"type": "invoice",
"id": "in_1P...",
"customer_id": "cus_..."
},
"schema_version": "1.0",
"raw_body_base64": "...",
"signature_verified": true,
"delivery": {
"attempt": 1,
"source_ip": "203.0.113.10"
}
}
Decision rule: if the provider supplies a globally unique event ID, use it as the core of your idempotency key. If not, derive a key from stable fields like provider + event_type + external_object_id + occurred_at rounded to a safe granularity. Avoid hashing the entire payload because minor field reordering can break dedupe.
Also store a small processing state record:
- status: received, queued, processing, succeeded, failed, dead_lettered
- last_error_category and last_error_message
- attempt_count and next_attempt_at
- crm_object_keys created or updated
Idempotency design for webhook-to-CRM writes
Idempotency must exist in two places: at the event level to prevent reprocessing and at the CRM write level to ensure safe replay even if your worker crashes mid-flight.
1) Event-level dedupe
When a worker starts processing an event it should first write a dedupe record keyed by idempotency_key. If the key already exists with status succeeded, skip the event. If it exists with processing, you can either skip (to avoid parallelism) or check a heartbeat timestamp to reclaim stuck work.
Retention should exceed the provider retry window. Shopify retries can span hours so a few days of dedupe retention is a safer default for most businesses. If you run monthly billing or backfills, consider 30 to 90 days.
2) CRM-level idempotent upserts
Use a stable external ID field in your CRM such as stripe_customer_id, shopify_customer_id or your app_user_id and always upsert by that key. Avoid create-only calls. This also neutralizes out-of-order delivery because an update arriving before a create becomes an upsert that creates the record with the latest known state.
A real-world ops insight: if you map multiple SaaS sources into the same CRM object, define a source-of-truth rule per field. For example, let billing status come from Stripe only, let shipping address come from Shopify only and treat your product app as authoritative for plan entitlements. Without this, duplicates are not your biggest problem, data thrashing is. For a deeper, repeatable methodology that covers idempotency, retries, rate limits, OAuth/token refresh, canonical mapping, monitoring and production testing, use our pillar guide: API Integration Engineering Playbook: Reliable API + Webhook Connections.
Retry and backoff that respects CRM rate limits
Retries are required because at-least-once delivery is the norm. The goal is to retry transient failures without overwhelming the CRM or creating duplicate side effects.
Classify errors
- Retryable: 429 rate limit, 408 timeout, 5xx responses, network errors.
- Conditionally retryable: 409 conflict, 422 validation errors that may resolve after mapping fixes or schema updates.
- Non-retryable: authentication errors, missing required identifiers, signature verification failures.
Backoff policy example
- Attempt 1: immediate
- Attempt 2: +30 seconds
- Attempt 3: +2 minutes
- Attempt 4: +10 minutes
- Attempt 5: +30 minutes then DLQ

Include jitter so many events do not retry at the same time. Also cap concurrency in the worker so CRM writes stay within your allowed rate. This is the tradeoff: higher concurrency reduces queue lag but increases the chance of 429s and cascading retries. If your CRM is the bottleneck, tune for steadiness not raw throughput.
If you use a queue system like SQS with Lambda, enable partial batch failure responses so one bad message does not cause the whole batch to retry and accidentally redo already successful CRM updates. AWS documents this behavior and configuration in their SQS event source guidance.
Dead-letter queue design and a practical reprocessing runbook
A DLQ is not a trash can. It is a controlled holding area for events that need human attention or a code fix. Every DLQ message should contain enough context to re-run safely.
What to include in the DLQ message
- Internal event_id and idempotency_key
- Provider and provider_event_id
- Error category, error message and last HTTP status
- Retry attempts and exhausted retry condition
- Target CRM object key if known
DLQ reprocessing workflow
- Identify the error class: mapping bug, missing identifier, CRM outage, permission issue or payload schema change.
- Deploy the fix or update mapping rules.
- Re-drive DLQ messages back into the main queue or trigger a dedicated reprocessor worker.
- Verify idempotency: confirm the worker checks idempotency_key before any CRM write so replay is safe.
- Close the loop: create a post-incident note and add a validation rule or test to prevent recurrence.
When this approach is not the best fit: if you only have a single low-volume integration and a missed update is acceptable, this architecture can be more operational overhead than you need. In that case, a managed automation tool can be fine. Once your CRM becomes revenue-critical or you rely on webhooks for provisioning, billing or support routing, the gateway becomes worth it.
Observability that makes ops trust the system
Webhook gateways fail quietly unless you instrument them. Providers often do not alert you quickly when deliveries fail so you need your own signals.
Logs
- Log at receipt: provider, provider_event_id, signature_verified, event_type and request_id.
- Log at processing: event_id, idempotency_key, crm_operation, crm_status_code and latency_ms.
- Log at failure: error_category, attempt_count, next_attempt_at and whether it went to DLQ.
Metrics and alerts
- Queue age (p95): alerts when processing falls behind, often before users notice.
- DLQ depth and oldest age: alerts immediately when non-retriable failures appear.
- Retry rate: spikes indicate CRM instability or rate limits.
- Dedupe hit rate: a sudden jump can indicate provider retries, gateway timeouts or duplicate subscription configuration.
- End-to-end success rate: received events vs succeeded CRM commits.
Set one SLO that the business can understand: for example, 99% of webhook events are applied to the CRM within 5 minutes. This turns integration health into something you can manage.
Implementation checklist for a production-ready webhook gateway
- Verify signatures using the raw body before JSON parsing and reject unverifiable requests.
- Return a fast 2xx after verification and persistence. Do not call the CRM in the request thread.
- Persist raw payload plus a normalized envelope with schema_version for safe evolution.
- Create an idempotency_key and record it before any side effect.
- Upsert in the CRM using external IDs not create-only operations.
- Classify errors and implement retry with backoff and jitter for retryable cases only.
- Send exhausted or non-retriable events to a DLQ with triage metadata.
- Dashboards for queue lag, DLQ depth, success rate and CRM 429s plus alerts routed to the right owner.
- Add a reconciliation job for critical entities if missing updates are unacceptable. For example, nightly pull of recent invoices or orders to repair gaps.
How ThinkBot Agency implements this in n8n and custom code
At ThinkBot Agency we typically implement the gateway pattern as a small hardened ingest service plus an asynchronous workflow layer. For many teams, n8n is a great fit for the worker and CRM adapter steps because it provides fast iteration, strong API connectivity and clear operational visibility when paired with proper logging and queueing. For a concrete example of unifying CRM and other go-to-market systems with idempotent upserts, pagination patterns, and 429 handling, see API Integration Solutions That Unify CRM, Email, and Support Data Using Custom n8n Workflows. For high-volume or strict latency cases we add lightweight custom code at the edge for signature verification and event persistence then let n8n or a worker service handle the controlled processing.
If you want help standardizing this across Stripe, Shopify and your product webhooks, book a consultation and we will map your providers, CRM constraints and retry windows into a concrete design you can reuse across integrations: book a consultation.
To see the kinds of automation systems we deliver for ops, marketing and support teams, you can also review our work: portfolio.
FAQ
Common questions we hear when teams implement a webhook gateway for CRM delivery.
How fast should my webhook endpoint respond?
As fast as possible, ideally within a few seconds. Treat the endpoint as verify-then-queue: verify signature, store the event durably and acknowledge with 2xx. Do not perform CRM writes in the request handler because timeouts trigger provider retries and duplicate deliveries.
What should I use as an idempotency key?
Prefer the provider event ID when available because it is designed to be unique. If a provider does not include one, derive a stable key from provider name plus event type plus the external object ID and a stable timestamp. Store the key before any CRM call and use it to skip already-succeeded events.
How many retries should I allow before sending to a dead-letter queue?
For most webhook-to-CRM workloads, 5 attempts with exponential backoff and jitter is a practical default. It gives transient CRM issues time to recover while keeping your queue from stalling indefinitely. Non-retryable errors should go to the DLQ immediately with clear error metadata.
How do I prevent duplicates if my worker processes a message twice?
Assume at-least-once delivery and make downstream actions idempotent. Use a dedupe record keyed by idempotency_key and implement CRM upserts by external ID. With both layers, retries and replays become safe even if the same event is delivered multiple times.
Do I still need reconciliation jobs if I have this gateway?
Sometimes yes. A gateway reduces dropped updates but it cannot eliminate all risk such as provider subscription deletion after repeated failures or long outages. For critical objects like paid invoices, subscriptions or high-value orders, a periodic API pull to reconcile recent changes provides an extra safety net.