
SaaS vendors change APIs all the time: endpoints get deprecated, fields shift shape, auth flows tighten and rate limits change. If your workflows push data into a CRM or finance system those changes do not just cause errors, they can quietly corrupt records and create weeks of cleanup. This post is for operators and builders who own integrations and want a repeatable way to ship updates safely. You will see API integration best practices focused specifically on surviving upstream change with version pinning, contract validation, staged rollout, monitoring for silent drift and fast rollback.
At a glance:
- Pin vendor API versions and treat SDK upgrades and API version upgrades as separate risk events.
- Add contract and schema checks in CI so breaking changes fail before they ship.
- Roll out integration updates in stages with feature flags and canary exposure.
- Monitor not only 4xx and 5xx but also data-quality signals that catch silent corruption.
- Use a rollback plan that can revert behavior and data writes safely.
Quick start
- Pin versions now: set a fixed vendor API version header or SDK setting and record it in your repo.
- Add a CI gate: run OpenAPI breaking-change detection (if you have specs) and contract tests for your API client.
- Split environments: dev and stage should use separate vendor credentials, webhooks and rate-limit budgets.
- Ship behind a flag: deploy the new mapping logic disabled by default then enable for a small canary segment.
- Watch data quality: compare canary vs baseline for null rates, enum drift and duplicate creation in downstream systems.
- Promote or roll back: promote only when acceptance criteria pass and keep rollback steps rehearsed.
To survive SaaS API changes you need an operational boundary around third-party calls: pin the version you expect, prove the payload and behavior with contract tests and schema validation, roll out changes gradually with flags and canaries and monitor downstream data quality. When something regresses you should be able to roll back quickly without sending bad writes into your CRM or accounting platform and without leaving partial updates that require manual cleanup.
Why upstream API changes are the most expensive integration failure
Most teams plan for hard failures: 401s, 429s and timeouts. The more costly failures are partial breakages where calls still return 200 but the meaning of fields changed or an optional field became required and your mapping silently drops data. Common real-world examples we see when cleaning up integrations:
- Payload drift: a nested object becomes an array or a string becomes an object and your deserializer falls back to defaults.
- Enum changes: vendors add new status values and your downstream mapping collapses them into an existing bucket.
- Webhook shape changes: you parse events but miss new required fields, leading to incomplete records.
- Auth and scope tightening: tokens still work for some endpoints but not others, creating inconsistent behavior.
- Rate-limit policy changes: retries amplify load and create duplicates in the CRM when idempotency is not enforced.
The operating goal is simple: make upstream change predictable. You cannot control a vendor roadmap but you can control how changes enter your system and how quickly you detect and contain issues.
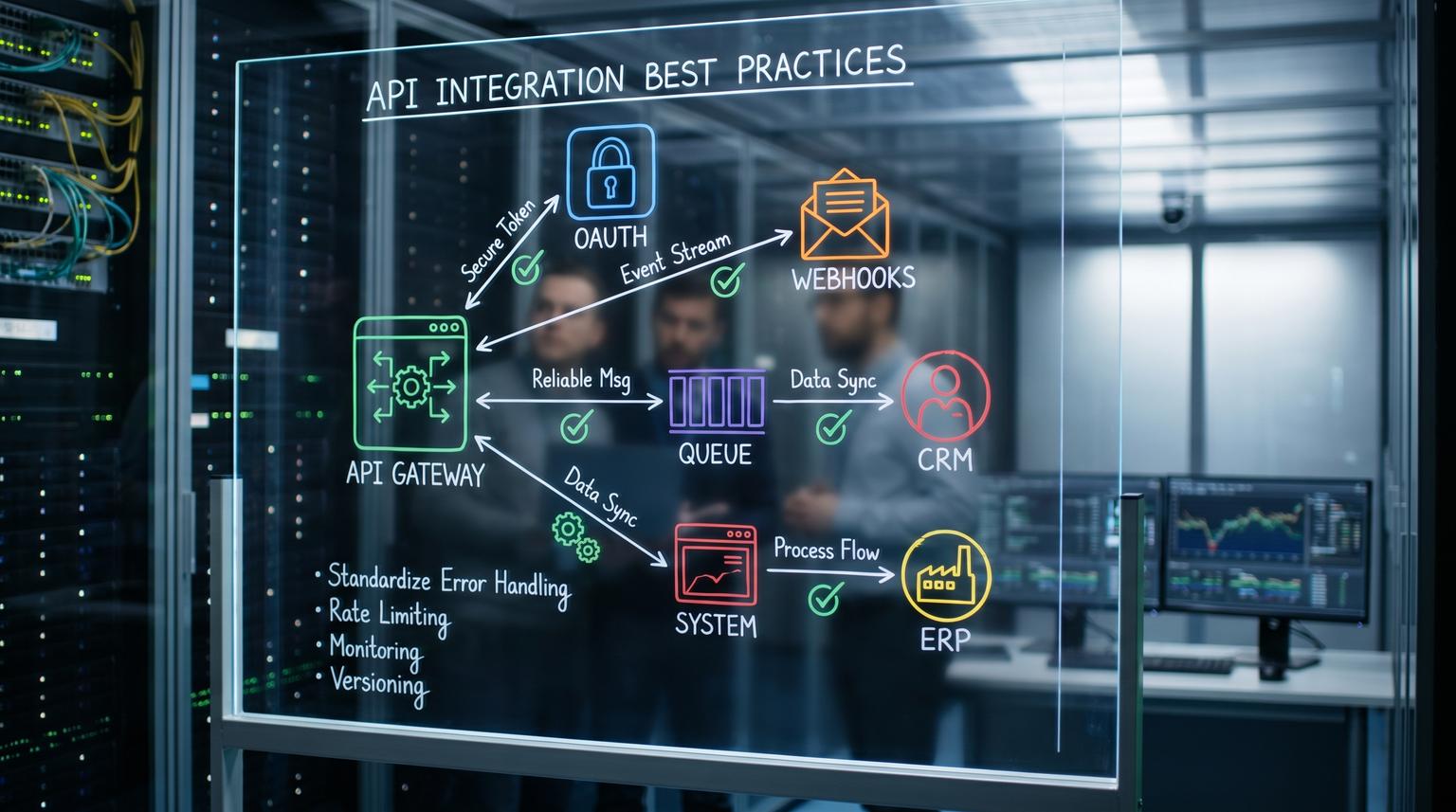
Build a change boundary around the vendor API
The easiest way to reduce blast radius is to treat vendor calls as a product interface inside your stack. Even if you use n8n, Zapier or Make, you can still implement this boundary by centralizing third-party calls in one place (a single workflow, a shared custom node or a thin API service) and having the rest of your automations call that boundary.
What this boundary should include
- Version controls: explicit API version pins and a place to record what you pinned and why.
- Validation: schema checks for inbound and outbound payloads and contract tests for key behaviors.
- Feature flags: the ability to switch mapping logic, endpoints or auth modes without redeploying everything.
- Idempotency and replay: stable id keys so retries and reprocessing do not duplicate writes.
- Audit trails: correlation IDs from vendor request to downstream write to support ticket.
A decision rule we use with clients: if the integration writes to revenue, invoicing, fulfillment or pipeline stages it should go through a controlled boundary. If it only reads data for a dashboard and the impact is low the overhead may not be worth it. For a broader view of how this boundary enables automation outcomes, see How Custom API Integration Powers Automation, Workflow Efficiency, and Scalable Growth.

Version pinning that actually prevents surprise changes
Many teams believe they are safe because they use an official SDK. In practice an SDK upgrade can pull you onto a new API version or a different default behavior depending on the vendor. Stripe documents this clearly and shows how to explicitly set an API version in SDKs and headers. See Stripe API versioning and set version.
Pin the API version in one place
- Global pin in the client: easiest and most consistent when all calls should behave the same.
- Per-request pin: useful when migrating endpoint-by-endpoint while keeping most calls stable.
- Header pin for raw HTTP: helpful in automation tools that let you set headers directly.
One tradeoff: in strongly typed SDKs you often cannot safely target an arbitrary API version because response object types may not match. Treat SDK bump and API version bump as separate change events and test them separately.
Practical acceptance criteria for a version pin
- The pinned version is stored in code and in an ops runbook.
- CI fails if the pin changes without an associated changelog link and rollout plan.
- Webhooks and event payloads are validated against the pinned expectations.
- Downstream writes remain idempotent and do not create duplicates during retries.
Contract testing and schema checks as deploy gates
Version pinning reduces surprise but it does not eliminate it. Vendors can still deprecate endpoints or change behavior behind a version boundary. This is where contract tests and spec diffing become your early warning system. If you want a deeper, end-to-end reliability methodology (idempotency, retries, rate limits, and production readiness), use our pillar: API Integration Engineering Playbook: Reliable API & Webhook Connections.
Consumer-driven contract tests for critical behaviors
Consumer-driven contracts capture what your integration expects from a vendor and turn that into a versioned artifact you can verify. Pact is a common approach and its consumer test flow is documented here: Pact consumer tests.
The implementation detail that makes this valuable: test your real API client code path, not a raw HTTP call. That keeps the contract aligned with your production mapping and error handling. In CI, clear the pact output directory so old interactions do not create false confidence.
Minimal skeleton showing the idea:
const { Pact } = require("@pact-foundation/pact")
// Create Pact, start mock, define interaction, execute your real client code
// and then validate to generate the pact file.
OpenAPI breaking-change detection for structural drift
If the vendor publishes an OpenAPI spec or you maintain your own proxy spec, you can automatically detect breaking changes in pull requests. oasdiff is built for this and supports CLI and GitHub Actions. See oasdiff breaking change detection.
# install
brew install oasdiff
# fail CI on breaking changes
oasdiff breaking base.yaml revision.yaml
# optional: generate a changelog
oasdiff changelog base.yaml revision.yaml
Acceptance criteria for the contract gate
- Contract tests cover the top write paths (create/update) and at least one read path used for reconciliation.
- Schema validations fail on missing required fields, unexpected nulls and type changes.
- CI blocks merges when the spec diff reports breaking changes unless a migration plan exists.
- All tests run deterministically without calling the live vendor API.
Staged rollout across dev stage and prod with canaries and feature flags
Even with strong tests, integration changes can still fail in production because real data is messy, rate-limit behavior differs and some vendors vary behavior by account settings. You need controlled exposure and a way to turn off the new behavior fast.
Environment discipline
- Separate credentials: different API keys, webhook endpoints and scopes for dev, stage and prod.
- Mirrored configuration: keep timeouts, retry policies and pagination consistent across environments.
- Representative test fixtures: include edge cases like missing addresses, empty line items and canceled subscriptions.
Canary rollout mechanics
A practical model is canary traffic splitting. AWS API Gateway documents how a stage can run a base deployment plus a canary deployment with a configurable traffic percentage, separate logs and fast disable for rollback. See API Gateway canary release.
You can apply the same idea even if you are not using API Gateway:
- Route a small percentage of jobs or tenants through the new mapping.
- Use a flag to switch endpoint versions or auth modes for only the canary segment.
- Keep base and canary metrics separate so you can compare quickly.

Promotion criteria that include data quality
Only promote when both reliability and correctness are proven. Example acceptance criteria:
- Error rate: canary non-2xx stays within your normal baseline plus an agreed margin.
- Latency: p95 latency does not exceed baseline by more than a threshold that would cause queue buildup.
- Write correctness: downstream records created/updated match expected counts and do not increase duplicate rate.
- Field integrity: key fields (email, amount, currency, external IDs) do not show increased null or default values.
- Rate-limit health: 429s stay below a threshold and backoff behaves as expected.
Monitoring that catches silent data corruption not just outages
Most integrations alert only on failed executions. That misses the most expensive class of bugs: wrong values successfully written to downstream systems. Monitoring should include both system metrics and data-quality metrics.
System signals
- 4xx and 5xx rates by endpoint and by tenant
- 429 rate-limit responses and retry counts
- Queue length and job age for scheduled syncs
- Webhook delivery lag and signature verification failures
Data-quality signals (the ones that save you)
- Null rate drift: percent of records missing required fields after mapping.
- Enum drift: appearance of new status values that your mapping does not recognize.
- Duplicate creation: spikes in create operations relative to updates for the same external ID.
- Reconciliation deltas: nightly count and sum checks between vendor and CRM or accounting totals.
- Outlier detection: amounts, quantities or timestamps outside expected ranges.
A real operations insight: the fastest way to spot silent corruption is to add a small set of invariant checks that run after every batch. For example: every invoice must have currency, total and customer external ID. If any are missing, quarantine the batch and alert. You would rather block a handful of writes than spend a day untangling a pipeline full of half-valid records.
Breaking API change checklist with example acceptance criteria
Use this as a repeatable release process whenever a vendor announces a deprecation, you bump an SDK or you see payload drift in logs.
| Step | What to do | Example acceptance criteria |
|---|---|---|
| 1) Pin and document versions | Set explicit API version headers or SDK config. Record current pin, target pin and vendor changelog links. | Pin is enforced in code. Any change requires PR review and a rollback plan. |
| 2) Detect breaking changes early | Run spec diffs (oasdiff) if you have specs. Add schema validation for key payloads. | CI fails on removed fields, type changes or requiredness changes without a migration. |
| 3) Prove behavior with contract tests | Add consumer-driven contract tests around your API client behavior and publish contracts as a build artifact. | Contract tests cover create/update and webhook parsing. Tests run without live vendor calls. |
| 4) Stage rollout behind flags | Deploy new mapping code disabled. Enable for internal users or a small tenant set. Keep base path intact. | Flag can be toggled without redeploy. Canary segment can be narrowed to one tenant. |
| 5) Monitor reliability and data quality | Dashboards for canary vs base. Add null-rate and duplicate-rate checks plus reconciliation deltas. | No increase in null-rate for required fields. Duplicate creations do not exceed a set threshold. |
| 6) Roll back safely | Disable flag or revert routing. Pause writes if needed. Re-run from last known good checkpoint. | Rollback completes in minutes. No further bad writes occur and backlog drains predictably. |
Common failure pattern to avoid
Teams often change mapping logic and endpoint versions in the same deploy then try to debug under pressure. Split those changes. First ship the new mapping with the old version pin and validate. Then upgrade the pin with the same mapping. This isolates risk and makes rollbacks simpler.
Rollback procedures that do not make the data problem worse
Rollback is not just reverting code. For integrations that write to CRMs and finance systems, rollback must prevent additional bad writes and provide a path to reconcile what already happened.
Rollback sequence you can reuse
- Stop the bleeding: disable the feature flag or canary route and pause write operations if corruption is suspected.
- Switch to safe mode: fall back to read-only syncs or store events for later replay rather than writing.
- Identify the affected window: use correlation IDs to find jobs or webhook events processed under the new behavior.
- Reconcile: compare counts and key fields between vendor and downstream for the affected objects.
- Repair: re-run from a checkpoint or apply targeted updates using external IDs and idempotency keys.
- Post-incident hardening: add a new invariant check or contract test based on what slipped through.
When this approach is not the best fit
If you are integrating with a tiny internal service that changes in lockstep with your workflow, the full contract testing and canary machinery can be overkill. In that case focus on version pinning, basic schema validation and strong logging. The full playbook pays for itself when the provider is external, changes independently and the integration writes business-critical data.
How ThinkBot Agency implements this in real automation stacks
In client environments we typically combine a controlled API boundary with automation tooling like n8n. The boundary handles version pins, retries, idempotency and validation while the workflows orchestrate business steps and approvals. This keeps your automations flexible without exposing every workflow to vendor churn.
If you want a second set of eyes on your highest-risk integrations or you need to harden an existing n8n or custom stack against vendor deprecations, book a working session and we will map your change gates, monitoring and rollback path end to end: Book a consultation.
For examples of the kinds of integrations we build and stabilize you can also review our work: Portfolio. If you are deciding whether to centralize these safeguards in middleware for larger org needs, compare patterns in API Integration for Enterprises: Secure, Scalable Middleware That Keeps CRM, ERP and Support in Sync.
FAQ
Common follow-ups we hear from teams maintaining CRM, billing and support integrations.
How often should we upgrade a vendor API version pin?
Upgrade on a schedule you can support, not when a surprise deprecation forces you. Many teams do quarterly reviews of vendor changelogs and plan version upgrades only after contract tests, staged rollout and data-quality checks are in place.
Do we need both OpenAPI diffing and contract tests?
They solve different problems. OpenAPI diffing is great at detecting structural breaks like removed fields or type changes. Contract tests validate the behaviors your integration depends on such as how errors are returned or how a create call responds. Using both reduces false confidence.
What should we monitor besides errors and latency?
Monitor correctness: null-rate drift for required fields, enum drift, duplicate creation rates and reconciliation deltas between the vendor and your CRM or finance system. These catch silent corruption that can look like success in logs. For a practical deep dive on preventing duplicates specifically in webhook-to-CRM flows, see Stop Duplicate Contacts and Dropped Leads With API Integration for Business That Can Take a Hit.
How do we roll back if the vendor already processed writes?
Roll back your integration behavior first to stop further bad writes then reconcile using external IDs, idempotency keys and a defined affected time window. In some cases you switch to read-only mode while you repair downstream records and replay from a checkpoint.
Is this possible with no-code and low-code tools?
Yes. You can pin versions with headers, centralize API calls in a shared workflow or thin service, validate schemas, gate deployments across dev stage and prod and use feature flags to control routing. The key is operational discipline and consistent monitoring not the tool choice.