
When your CRM, email marketing platform, and helpdesk each hold a different version of the customer, you get duplicates, missing context, and reporting you cannot trust. This is where API integration solutions become operationally important, not just technical, because they create one reliable data flow across tools.
This guide is for ops leaders, marketing and CRM teams and tech-savvy founders who want a practical blueprint for unifying customer data with custom n8n workflows. We will cover proven integration patterns, data modeling decisions and the production guardrails that prevent drift over time.
Quick summary:
- Design a canonical customer profile so every system maps to one source of truth.
- Use webhooks for fast changes and scheduled syncs for backfills and drift correction.
- Build reliability with pagination, rate-limit handling, retries and idempotent writes.
- Add audit trails and human approvals for edge cases like merges and ambiguous matches.
Quick start
- Pick your source of truth for each entity (contact, company, ticket, subscription) and define a canonical schema.
- List your key events (new lead, email engagement, ticket created, customer status change) and decide webhook vs scheduled sync per event.
- Implement an integration ledger with external IDs and idempotency keys for every write.
- Build a paginated incremental sync for historical data and nightly drift checks.
- Add rate-limit handling for 429 and transient errors with retries and backoff.
- Deploy with an n8n error workflow for alerting, triage and replay.
To unify CRM, email and support data you typically combine event-driven webhooks for near real-time updates with scheduled incremental syncs for completeness. A canonical customer profile aligns fields across tools while pagination, throttling controls, retries and idempotent upserts prevent duplicates and data drift. In n8n this becomes a set of modular workflows backed by a ledger table that tracks external IDs, last sync checkpoints and audit logs. If you are comparing platforms before implementing this, see our Zapier vs. n8n comparison for scalability and data-control tradeoffs.
Why unifying CRM, email, and helpdesk data breaks in real life
Most teams start with simple point-to-point automations. It works until volume increases, edge cases show up and different departments evolve their processes. Common failure patterns we see when we audit integrations include:
- Duplicate contacts because each tool creates its own record and matching rules are inconsistent.
- Data drift where fields like lifecycle stage, consent status, owner and company association differ across systems.
- Partial context because tickets do not include marketing engagement history and sales lacks recent support risk signals.
- Unreliable reporting when dashboards pull from multiple sources without consistent IDs and timestamps.
- Silent failures due to rate limits, pagination limits or schema changes that do not alert the right person.
The fix is not more one-off zaps. It is an integration design that treats these tools as a distributed system with explicit contracts, retries and auditability.
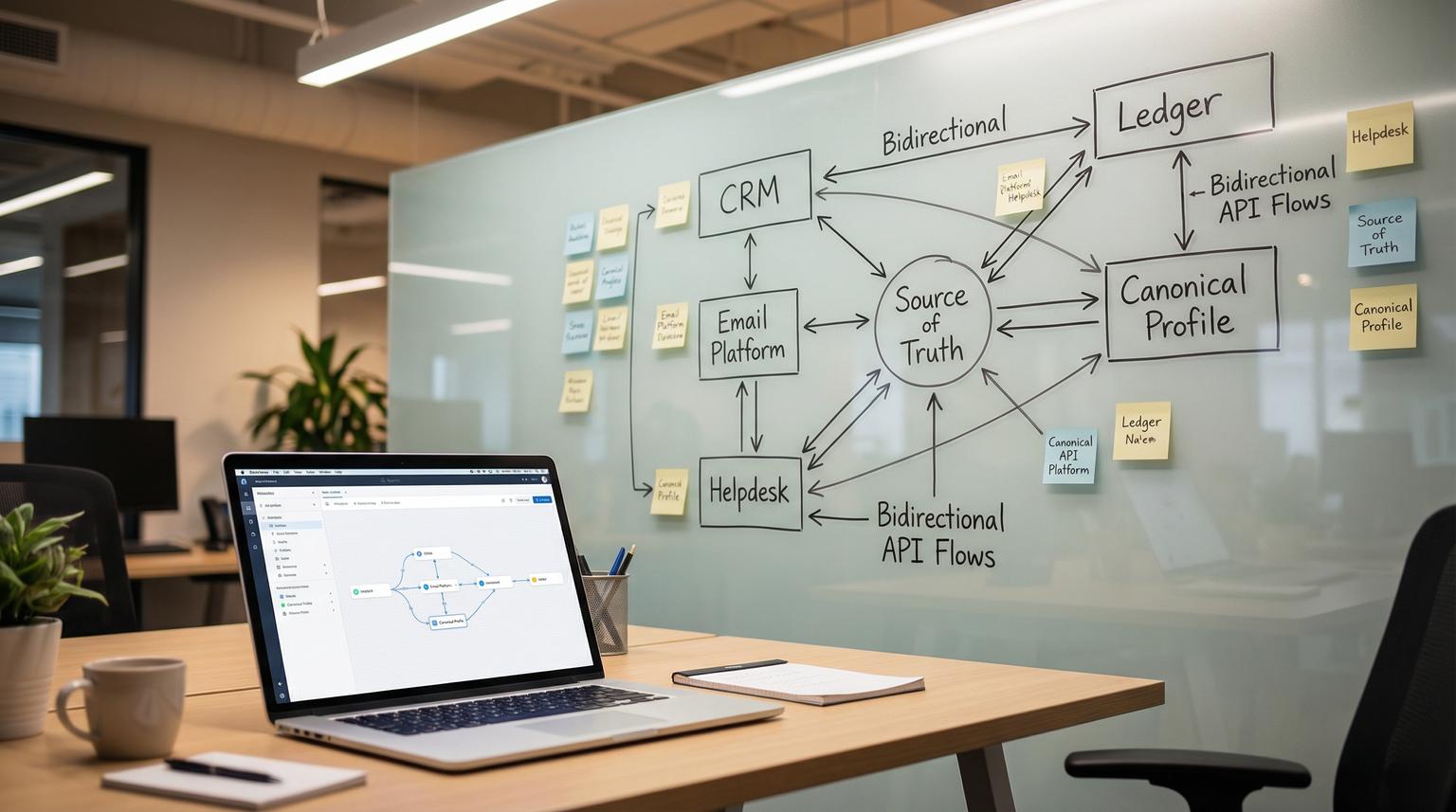
Core architecture: canonical customer profile and field mapping
Before building workflows, you need a shared model. ThinkBot Agency typically starts by defining a canonical customer profile that can represent any person or company across your stack. You then map each system to that schema and enforce stable identifiers.
Define the entities and ownership rules
A common set of entities looks like this:
- Person: email, phone, name, consent status, lifecycle stage, owners.
- Company: domain, name, segment, account owner.
- Conversation or ticket: ticket ID, category, priority, sentiment signals, last response time.
- Marketing engagement: campaign, last email open or click, unsubscribe, lead score inputs.
Next, define which system is authoritative per field. Example: CRM owns lifecycle stage and account owner, helpdesk owns ticket status and last reply timestamps and email platform owns subscription status and consent events.

Use stable IDs and an integration ledger
Do not rely on email alone as your primary key. People change emails and shared inboxes exist. The best practice is to maintain:
- External IDs per system (crm_contact_id, email_subscriber_id, helpdesk_user_id).
- A canonical ID inside your integration layer (canonical_person_id).
- A ledger record that links them and stores last sync timestamps, last seen hashes and reconciliation notes.
This ledger can be a simple Postgres table or a lightweight data store. It becomes the backbone for deduping, auditing and safe retries.
Example canonical profile template
Use this template when you align fields across tools and when you brief stakeholders on what the unified profile includes.
{
"canonical_person_id": "uuid",
"identifiers": {
"email": "[email protected]",
"phone": "+15551234567",
"crm_contact_id": "12345",
"email_platform_id": "abcde",
"helpdesk_user_id": "u_987"
},
"profile": {
"first_name": "Ava",
"last_name": "Ng",
"company_domain": "company.com",
"country": "US",
"timezone": "America/New_York"
},
"status": {
"lifecycle_stage": "customer",
"lead_source": "webinar",
"marketing_consent": "subscribed",
"do_not_contact": false
},
"support": {
"open_ticket_count": 1,
"last_ticket_id": "TCK-10021",
"last_ticket_priority": "high",
"last_reply_at": "2026-02-01T12:34:56Z"
},
"audit": {
"last_unified_at": "2026-02-01T12:35:10Z",
"last_source_system": "helpdesk",
"last_source_event_id": "evt_123"
}
}
Integration patterns that keep data consistent
Unification is usually a mix of push and pull. The goal is to minimize latency without sacrificing correctness. For more implementation ideas, read our guide on API integration for business automation across CRM and lifecycle journeys.
Webhooks for real-time changes
Use webhooks for events that should update other systems quickly, such as new lead submissions, subscription status changes and ticket priority escalations. In n8n this is typically a Webhook Trigger workflow that validates payloads, resolves canonical IDs then writes updates to the relevant tools.
Webhooks should be treated as unreliable. Build for retries and for out-of-order events. Your ledger should record the source event ID and timestamp so you can ignore older events.
Scheduled incremental syncs to prevent drift
Even with webhooks you will eventually miss events due to downtime, permission changes or provider outages. A scheduled incremental sync (every 15 minutes, hourly or nightly) is your safety net. It pulls records updated since the last checkpoint and reconciles differences.
When dealing with list endpoints you almost always need pagination. A practical approach is to persist your cursor or updated_at checkpoint and process each page immediately instead of building huge arrays in memory. The pagination basics are well explained with pagination patterns that apply to any workflow tool.
Handling pagination without timeouts and memory blowups
- Prefer cursor-based pagination when the API offers it.
- Process page-by-page and write results as you go.
- Update your checkpoint after each successfully committed page.
- Stop safely before workflow runtime limits and resume from the last checkpoint.
Production reliability checklist for custom n8n workflows
Use this checklist when you promote an integration from a prototype to production. It is designed for CRM, email and helpdesk unification where failure modes tend to be repetitive and costly.
- Attach a dedicated n8n error workflow using the Error Trigger so failures are centralized and actionable, following the approach in the error handling docs.
- Log execution context on failures: workflow name, execution ID, last node executed and the failing external ID.
- Implement an integration ledger table to store external IDs, canonical ID and last successful sync timestamps.
- Validate required fields early and fail fast using a Stop And Error node when mapping rules are violated.
- Design idempotent writes using upserts or stable idempotency keys so retries never create duplicates.
- Handle pagination in a resumable way by persisting cursor or last_seen timestamp after each page commit.
- Cap outbound concurrency and implement delays for providers with strict rate limits.
- Explicitly handle 429 and 503 responses, honoring Retry-After when present.
- Record request and response metadata needed for audit: source event ID, destination record ID and update type.
- Create a replay path that can reprocess a single ledger item without re-running the entire sync.

Retries, rate limits, and idempotency without duplicates
Reliability is not only about catching errors, it is about making retries safe. Most teams accidentally build at-least-once behavior, which creates duplicates when an API times out and the workflow retries.
Rate-limit handling with Retry-After
When an API responds with HTTP 429 Too Many Requests or 503 Service Unavailable your workflow should slow down and try again. Many APIs include a Retry-After header that tells you how long to wait. MDN documents the header formats Retry-After and it is worth implementing both seconds and date forms.
In n8n you can implement this by checking the HTTP node response code and headers then using a Wait node with a computed delay. Add a max retry count and jitter so you do not create synchronized retry storms.
Idempotency: the guardrail that prevents duplicates
Idempotency means you can safely retry a mutating operation and the outcome is the same as if you had done it once. This is a core reliability practice in distributed systems and the AWS guidance on idempotent operations maps directly to CRM and helpdesk writes.
Practical patterns we use:
- Upsert by external ID whenever the destination supports it (preferred).
- Idempotency keys derived from stable identifiers like source_system + object_type + source_record_id + operation, not timestamps.
- Integration ledger records the idempotency key and the destination record ID so a retry can check before writing.
Human-in-the-loop approvals for edge cases
Some situations should not auto-resolve:
- Potential duplicate contacts where two people share the same email domain and similar names.
- Conflicting consent states between systems.
- Company merges or domain changes.
- Ticket-to-account linkage when the requester email is not in the CRM.
In these cases route the item to a review queue. In n8n this might be a task record in your CRM, an internal email or a helpdesk ticket tagged for ops. Once approved, the workflow continues and logs who approved it and when. If you want more patterns for robust governance as volume grows, see our Zapier automation for enterprises guide (principles apply beyond Zapier).
Example n8n architecture for lead-to-customer handoffs and support enrichment
Below is a practical architecture we often implement for clients who need unified customer context and reliable reporting. It is designed to be modular so you can swap providers without rewriting everything.
Workflow 1: Lead intake and enrichment (webhook-driven)
- Trigger: website form webhook or email platform lead event.
- Validate required fields, normalize email and phone.
- Resolve canonical_person_id using the ledger.
- Upsert contact in CRM, attach lead source and campaign.
- Write back CRM ID to the ledger and tag in email platform.
Workflow 2: Ticket enrichment and routing (event-driven)
- Trigger: helpdesk ticket created or priority changed.
- Look up canonical profile and recent marketing engagement.
- Enrich ticket with account tier, lifecycle stage and owner.
- If VIP or churn risk, notify the owner and create a CRM task.
- Log enrichment actions to the audit trail.
Workflow 3: Incremental sync and drift correction (scheduled)
- Schedule: every hour for high change systems, nightly for slow-moving fields.
- Pull updated records using updated_at cursors and pagination.
- Compare to canonical schema and reconcile based on field ownership rules.
- Write changes with idempotent upserts and record outcomes in the ledger.
Workflow 4: Central error workflow and observability
Attach an error workflow to every production workflow in n8n. When any run fails the error workflow captures execution metadata, routes an alert to the right channel and optionally opens a triage ticket. This design is recommended by n8n in their error workflow guidance and it is one of the simplest ways to increase reliability quickly.
Security and audit trails that hold up in reviews
- Store credentials in n8n credentials vault and restrict access by role.
- Minimize PII in logs, store only IDs and necessary metadata.
- Keep an audit table with source event ID, destination record ID, action type, timestamp and execution URL.
- Use least-privilege API keys per system and rotate keys on a schedule.
If you want this architecture implemented for your stack, ThinkBot Agency can build it as a set of maintainable n8n workflows plus the supporting ledger and monitoring. The fastest way to scope it is a short discovery call, book a consultation and we will map your systems, data model and reliability requirements.
Prefer to vet delivery history first? You can also review our automation work on Upwork.
FAQ
These are the questions we hear most when teams plan a unified CRM, email and support integration.
What should be the source of truth when multiple tools store customer fields?
Pick a field-by-field ownership model. For example, the CRM can own lifecycle stage and account owner, the email platform can own consent and subscription state and the helpdesk can own ticket status and response metrics. Document these rules and enforce them in your sync workflows so you do not get update loops.
How do you prevent duplicate contacts when syncing CRM, email, and helpdesk?
Use a canonical ID and an integration ledger that maps each system record ID to that canonical profile. For writes, prefer upserts by external ID and use idempotency keys for create operations. Add a human approval step for ambiguous matches instead of guessing.
Do custom workflows in n8n scale better than one-off automations?
Yes when they are designed as modular workflows with shared components like normalization, ID resolution, a ledger, and centralized error handling. This creates consistent behavior across systems and makes it easier to monitor, replay failed items and evolve mappings as your process changes.
What is the minimum monitoring you need for API-based integrations?
Track failure rates, 429 throttling frequency, average API latency, records processed per run and drift counts detected by scheduled syncs. Also store audit logs that can answer who changed what and why, including the source event and the workflow execution reference.
Can ThinkBot Agency integrate our CRM with email marketing and helpdesk even if we have custom fields?
Yes. We start by defining a canonical schema that includes your custom fields and business rules then map each system to it. We implement the workflows in n8n with secure credential handling, an integration ledger and production guardrails like retries, backoff and idempotent writes.