
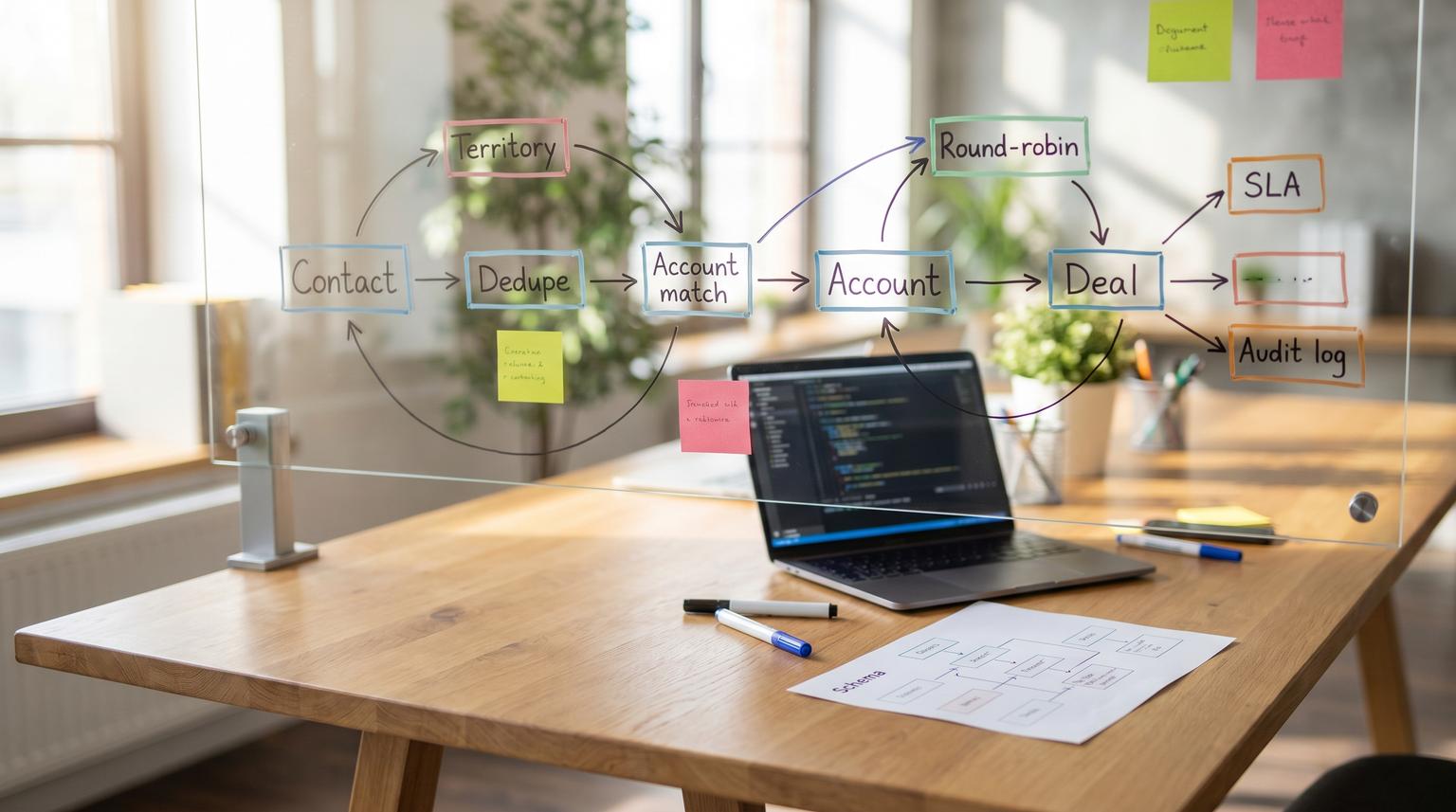
Most CRM problems are not caused by a lack of tools. They come from unclear definitions, inconsistent data, and automations that were built piecemeal until no one can explain why a record moved, who owns it, or whether the dashboard is telling the truth. This playbook gives you a repeatable CRM automation framework for designing lead routing, lifecycle stage transitions, pipeline hygiene, and revenue reporting that stays reliable as volume grows.
It is written for operators, RevOps, marketing, and sales leaders who want consistent handoffs, fewer manual updates, and reporting that matches reality. Integrations are treated as supporting connectors, not the process itself.
At a glance:
- Start with architecture: objects, associations, and structured fields decide what automation and reporting can safely do.
- Route leads with explicit precedence, dedupe and account match first, then territory, then round-robin pools with SLAs.
- Define lifecycle stages as auditable events with clear triggers, timestamps, and acceptance outcomes.
- Use objective activity signals (calendar, e-sign, billing) to keep pipeline stages and close dates current.
- Run data hygiene as an operating system: prevent bad inputs, dedupe with survivorship rules, and audit quality continuously.
- Govern automation like releases: testing, approvals, monitoring, and rollback to protect revenue reporting.
Quick start
- Map your CRM objects and required associations (Contact, Company/Account, Deal, Ticket) and decide what each record type owns.
- Standardize the 10-20 fields that power routing, lifecycle, and reporting into structured types (picklists, booleans, dates) and lock down free-text alternatives.
- Write a lead routing precedence spec: dedupe -> account match -> territory -> pool eligibility -> distribution -> SLA escalation.
- Define lifecycle stages as a state machine with entry criteria, exit criteria, and required fields at each handoff.
- Implement activity-driven pipeline updates from verifiable events (meeting held, proposal sent, invoice paid) with audit fields.
- Stand up data hygiene routines: validation on entry, dedupe rules + merge policy, enrichment guardrails, and a quarterly quality score.
- Ship automations using a release checklist: tests, approvals, deployment window, post-deploy verification, and rollback plan.
A scalable CRM automation system starts with stable data architecture, then layers routing, lifecycle transitions, and pipeline updates on top of controlled fields and auditable events. Build routing with clear precedence and SLAs, treat stage changes as logged handoffs, and use objective signals from calendar, billing, product, and support to keep pipeline current. Finally, protect reporting with a hygiene operating system and release governance so automation changes do not silently break attribution, forecasting, and revenue dashboards.
Table of contents
- Why CRM automation fails in production
- Architecture before automation: objects, fields, associations
- Lead routing design: precedence, territories, pools, SLAs
- Lead routing precedence template you can copy
- Lifecycle stages and automated handoffs (MQL -> SQL and beyond)
- Pipeline integrity: activity-driven updates and stale deal control
- Data hygiene operating system: prevent, detect, repair, measure
- Revenue reporting and attribution guardrails that keep dashboards honest
- Integration patterns that support the process (without tool-driven chaos)
- Governance for reliable CRM automation at scale
- Risk modes and guardrails for routing, hygiene, and sync
- Implementation examples across common stacks
- FAQ
Why CRM automation fails in production
Automation usually breaks for predictable reasons:
- Ambiguous definitions: teams disagree on what counts as MQL, SQL, or a qualified opportunity, so automations fight each other.
- Uncontrolled inputs: free-text fields like state, industry, and lifecycle notes become routing keys, then reports fragment (CA vs California).
- Scattered logic: routing rules live in multiple workflows, form tools, and spreadsheets, so precedence becomes unpredictable.
- No audit trail: the CRM cannot answer, "why did this lead go to that rep" or "what moved this deal stage" so trust erodes.
- Release without governance: small edits create regressions in routing, stage gates, and dashboards because changes were not tested or rolled back.
If you want a system that scales, treat CRM automation as product infrastructure. That means stable architecture, explicit process specs, and operational governance. We expand on the end-to-end view in revenue engine thinking, where the CRM is the system of record and automation enforces consistency across channels.
Architecture before automation: objects, fields, associations
Before you automate anything, decide what your CRM considers a "thing" and how things relate. Most CRMs revolve around contacts, companies/accounts, deals/opportunities, and activities. If those relationships are inconsistent, automations cannot reliably trigger and reports cannot roll up cleanly, as explained in this guide.
Define your ownership model (and make it automatable)
Ownership is more than a single "record owner" field. Many teams need separate fields for SDR owner, AE owner, and Customer Success owner. The key is to define which owner field controls routing, which controls task assignment, and which is used for reporting. If ownership is unclear, handoffs get stuck and your SLA metrics are meaningless.
Use structured fields for workflow branching
If a field is used in routing, lifecycle transitions, SLAs, or dashboards, it should be structured (picklist/enum, boolean, date, number). Free-text belongs in notes. Field type choices directly constrain what can be filtered and therefore what can be automated, a practical pitfall highlighted in this overview.
Set stage-level required fields as data-quality gates
A powerful pattern is enforcing required properties at specific deal stages so reps are not blocked early but must provide key data when it matters. In HubSpot, this is available as stage-level required properties, described in this explanation. The concept transfers to any CRM: enforce close date, amount, next step, and loss reason at the moment the stage changes, not on day one.
Lead routing design: precedence, territories, pools, SLAs
Lead routing is a system, not a single rule. The most reliable approach is to define routing precedence and make every step log its reason. A survey of routing strategies underscores the common patterns: round-robin for speed and fairness, territory routing for coverage, and account-based routing to protect existing ownership, as described in this overview.
Routing precedence: the order that prevents chaos
For most teams, the default order should be:
- Dedupe: do not create new records when one already exists.
- Account match: if the company already exists, route to the account owner (or the assigned pod).
- Territory: determine region coverage from normalized geo fields.
- Pool eligibility: filter out inactive reps, out-of-office, or capacity-limited users.
- Distribution: round-robin inside the eligible group.
- SLA: create a task, alert, and escalation path if there is no acceptance.
Combining territory filtering with round-robin distribution is a proven pattern: first narrow eligible reps by territory, then distribute within that pool. It reduces misroutes and keeps fairness inside each region, a pragmatic approach detailed in this guide.
Make acceptance explicit (assigned is not accepted)
Speed-to-lead fails when the process assumes assignment equals ownership. Add an "acceptance" status with timestamps so you can measure SLA adherence and escalate. This handoff discipline is a core recommendation in this process, which breaks routing success into trigger, enrichment, routing, acceptance window, and first contact logging.
If you want a practical "fast response" routing pattern, we also covered a tactical implementation in 5 minute SLA workflows, including fallback queues and escalation timers.
Lead routing precedence template you can copy
Use the template below as a one-page spec your RevOps and sales leaders can sign off on. Treat it as a versioned contract, not a builder-only document. This pattern is inspired by the routing precedence approach in this routing overview and the layered territory plus round-robin approach in this practical guide.

Lead Routing Precedence (highest to lowest)
1) Duplicate detection:
- If contact with same email exists -> attach activity; do not create new lead
- If lead with same email exists -> merge/update; keep earliest create date
2) Account match:
- If domain matches existing Account -> assign to Account Owner
3) Territory rules:
- If country/state in [X] -> territory = [Y]
4) Pool assignment within territory:
- If ICP tier = A -> route to AE pool
- Else -> route to SDR pool
5) Distribution:
- Round-robin among eligible users (active=true, capacity>0)
6) SLA enforcement:
- Create task due in 15 min; notify; escalate/reassign at 30 min
Logging:
- Write routing_reason, routing_version, and routing_timestamp
Implementation note: centralize this logic in one automation surface where possible. When rules are split across form tools, CRM workflows, and spreadsheets, precedence becomes emergent behavior, not a designed system.
Lifecycle stages and automated handoffs (MQL -> SQL and beyond)
Lifecycle automation is where alignment becomes operational. Your goal is to make stage transitions auditable events that are triggered by consistent criteria, then verified by the next owner in the chain.
Separate fit from intent to avoid over-promotion
Many teams promote leads based on activity alone, which floods Sales with poor-fit leads. A better model is Fit + Intent, where fit is defined by ICP attributes like company size, industry, geography, and tech stack and intent comes from behavioral signals. This multi-criteria approach is laid out in this blueprint.
Define handoff fields and enforce them at the handoff moment
At minimum, write an MQL trigger field, MQL timestamp, and a structured disposition after Sales review (accepted, rejected, recycle). The key is that rejections must have standardized reasons so rules can improve. The "acceptance window" and first contact requirements are described in this handoff process, and they are exactly what lets you measure throughput without politics.
Build a recycle path, not a dead end
Rejected SQLs should not disappear into "disqualified" without learning. Create a recycle stage with a required rejection reason and a re-engagement play. This closes the loop between Sales feedback and Marketing nurture so the system gets better over time.
For a broader view of building end-to-end customer journeys with automation, see customer journeys across lead, sales, and post-sale workflows.
Pipeline integrity: activity-driven updates and stale deal control
Pipelines drift when stage changes and close dates depend on manual updates. The fix is to use objective activity signals as triggers and to run stale-deal controls as both automation and ritual.
Use verifiable events to move stages
Good stage automation is tied to external proof: a completed meeting, an e-sign envelope sent, or an invoice paid. A clear trigger-action pattern is summarized in this 2026 guide. To keep trust high, always write audit fields such as stage_changed_by, stage_change_source, and stage_changed_at.
Stale deals: automate the detection, not the decision
A strong operating rhythm is to flag deals with no activity in X days, remind the owner, then escalate to a manager if they remain stale. The weekly pipeline sweep idea with criteria like "not closed and last activity older than 10 days" is detailed in these routines. Automate the reminders and dashboards, but keep a human decision gate for closing, pushing dates, or logging missing activity.
If your team uses n8n for these event-driven updates and two-way sync, we outlined tactical build patterns in n8n workflows, including webhook intake, validation, dedupe, and safe sync.
Data hygiene operating system: prevent, detect, repair, measure
Hygiene is not a one-time cleanup. It is an operating system that keeps your routing, segmentation, and reporting trustworthy. A practical hygiene model splits the work into deduplication, standardization, enrichment, and decay management, as described in this playbook.
Prevention: validate at entry, not after the damage
Use validation rules and controlled vocabularies on fields that drive automation: email format, phone formatting, state/country picklists, and required associations. The reason is simple: a workflow that expects "California" misses "CA" and your routing becomes random, a concrete example called out in this hygiene guide.
Detection and repair: dedupe with survivorship rules
Dedupe is not only matching, it is deciding what wins. Define:
- Matching keys (email, domain, fuzzy company name).
- Survivorship (which system or field wins on conflict).
- Merge approvals (what can be auto-merged vs needs human review).
This is where many teams benefit from a quarantine path: if the record fails validation or matching confidence is low, route it to an ops queue instead of forcing a bad auto-merge.
Measurement: a quality score you can track over time
To keep hygiene from becoming "invisible work," score it. A weighted scoring model across completeness, accuracy, freshness, consistency, uniqueness, validity, and enrichment coverage is proposed in this audit framework. The exact weights are less important than consistency and the habit of investigating drops after imports or integration changes.
Field governance: decide what is allowed to overwrite what
Enrichment is helpful until it overwrites curated truth. Create an overwrite policy per field, for example:
- Attribution fields (first-touch UTMs) should never be overwritten after capture.
- Owner fields should be restricted to routing automation and RevOps admins.
- Firmographic enrichment can update if it is stale, but should preserve a history timestamp.
Revenue reporting and attribution guardrails that keep dashboards honest
Revenue reporting fails when definitions drift and attribution breaks silently. The fix is to treat reporting inputs as production data products with QA and monitoring.
Protect the tracking chain from click to CRM
Attribution does not fail in one place, it fails as a chain: link tagging, landing page parameter handling, consent storage, hidden form fields, marketing automation mapping, CRM mapping, and finally dashboards. A practical "tracking failure audit" approach that checks each link is described in this audit. In CRM terms, that means you validate UTMs at form submit and verify the mapped fields on the created CRM record, not just in analytics.
Monitor for anomalies your team will actually notice
Build weekly checks that run automatically and alert when something is off:
- % of new leads missing utm_campaign.
- Spike in "Direct" or "Unknown" as a source.
- Mismatch between analytics conversions by channel and CRM leads by source.
Common attribution mistakes and reconciliation guardrails between analytics and CRM are discussed in this guide. Your goal is not perfect attribution. Your goal is consistent enough data to make decisions without being misled.
For a CRM-first audit approach that connects attribution, scoring, and lifecycle definitions, see CRM audit patterns that focus on trust restoration.
Integration patterns that support the process (without tool-driven chaos)
Integrations should carry signals into your CRM automation system, not dictate your process. The right pattern depends on latency needs, API quotas, and conflict risk.
Decide your "golden record" rules up front
Before you sync anything bidirectionally, decide the authoritative system per entity and sometimes per field. A master data authority framework and conflict resolution options (last-write-wins, field-level merge, manual review) are described in this overview. This matters because routing, lifecycle, and revenue fields are high impact. They should not be overwritten casually by external systems.
Choose push vs pull based on business criticality
Polling is simpler but introduces lag and burns API quotas. Webhooks are efficient but require resilient endpoints that can handle bursts. Tradeoffs between polling and event-driven sync are discussed in this guide. In practice:
- Lead creation and assignment should be near-real-time (webhook or event-driven).
- Enrichment refresh can be batch (scheduled).
- Billing status and contract events should be event-driven when possible because they affect revenue reporting.
Document mappings as a living registry
The most common integration failure is not "it broke," it is "it synced but meant the wrong thing." Maintain a mapping registry that states source fields, target fields, transformations, and overwrite rules. The need for documented mappings is emphasized in this architecture guidance and it is one of the highest leverage habits for long-term reliability.
Governance for reliable CRM automation at scale
Automation needs governance because business rules change. Without a release process, your automations will drift, regress, and quietly corrupt reporting.

Testing is a release gate, not a nice-to-have
Even low-code workflows should have test cases for happy paths and edge cases (missing territory, duplicates, permissions). A practical case for structured testing in Salesforce Flow is described in these best practices. The concept applies broadly: define inputs, expected outputs, and rerun tests whenever you change fields, stages, or routing pools.
Use a deployment process with rollback
Treat changes as deployments with dependencies and activation states. A release-management view of CRM automation includes version control, manifests that pin exact workflow versions, approvals, and rollback steps, as outlined in this overview. Even if you do not use enterprise tooling, you can still adopt the discipline: sandbox build, peer review, test run, deploy window, post-deploy verification, then monitor for 48 hours.
If you want help establishing this governance across tools like n8n, Zapier, Make, HubSpot, or Salesforce, ThinkBot often starts with a focused audit and rollout plan. Our approach is similar to what we describe in consulting engagements where reliability and reporting are first-class requirements.
Risk modes and guardrails for routing, hygiene, and sync
Use the list below as a design review tool before go-live and whenever you change fields, forms, routing pools, or sync direction. These failure modes are grounded in common CRM data modeling issues discussed in this overview, routing dependencies in this guide, hygiene prevention practices in this playbook and integration authority patterns in this overview.
Failure modes and mitigations
- Territory field is blank -> lead falls to a default owner and goes stale -> enrichment or normalization before routing, else send to a triage queue with SLA.
- Geo data is inconsistent ("CA" vs "California") -> routing and reporting fragment -> replace free-text with picklists, add normalization, block invalid values at entry.
- Round-robin pool contains inactive reps -> leads go cold -> eligibility filter (active=true, capacity>0) plus daily roster sync.
- Deals are not consistently associated to company/contact -> pipeline rollups and attribution fail -> enforce association rules at deal creation and gate late stages on primary contact association.
- Bidirectional sync overwrites owner or lifecycle fields -> handoffs break and audits become impossible -> define authority per field, restrict writers, and prefer unidirectional sync by default.
- Automation changes ship without tests -> silent regressions in routing and reporting -> minimum test suite for each trigger branch plus post-deploy reconciliation of key dashboards.
- Enrichment overwrites curated internal fields -> segmentation becomes wrong -> field-level overwrite policy with timestamps, manual review for sensitive fields.
Implementation examples across common stacks
The same framework can be implemented in different CRMs and automation layers. The goal is consistency: one routing spec, one lifecycle definition set, one hygiene system and one reporting contract.
Example pattern 1: Web form -> CRM -> Slack/Teams -> SLA tasks
- Intake webhook receives form payload including UTMs.
- Normalize fields (country/state picklists), validate email.
- Dedupe by email and domain match to existing account.
- Apply routing precedence, assign owner, write routing_reason and routing_version.
- Create task due in 15 minutes, notify assigned rep, start acceptance timer.
This pattern is often built with n8n for control and observability. If you need an end-to-end reference, our no-code platforms playbook covers practical rollout steps across multiple tools.
Example pattern 2: MQL promotion with enrichment gate and explicit disposition
- Trigger: score threshold crossed or high-intent form submitted.
- Write MQL_trigger and MQL_timestamp.
- Run enrichment to populate company, territory, and ICP tier.
- Route to SDR/AE pool, require acceptance.
- Disposition required: accepted, rejected (with rejection_reason), or recycle.
Example pattern 3: Activity-driven stage changes with exception paths
- Meeting held (calendar completed) -> move deal to next stage, create follow-up task.
- Proposal sent (e-sign envelope sent) -> stage update, notify owner, set next step date.
- Invoice paid (billing event) -> close won, set close date, lock attribution fields.
- Exception path: if trigger lacks a valid deal association, create an ops task to link records, do not guess.
Example pattern 4: Ongoing hygiene with quarterly audits
- Entry validation blocks invalid emails and uncontrolled picklist values.
- Weekly dedupe job flags candidates above confidence threshold.
- Monthly stale title/company refresh for key segments.
- Quarterly data quality score run with an investigation ticket if score drops more than a defined threshold.
When to bring in ThinkBot
If your CRM is already live but pipelines and dashboards are unreliable, it is usually faster to rebuild the core automation contracts (routing precedence, lifecycle state machine, mapping registry, and hygiene operating system) than to keep patching symptoms. If you want a scoped plan and an implementation estimate, book a working session here: book a consultation.
To see examples of automation builds across CRM, email, and ops stacks, you can also browse recent work.
FAQ
What is the difference between CRM automation and CRM integration?
Automation is the logic and governance that decides what should happen (routing, stage changes, tasks, SLAs). Integration is the transport layer that moves signals between systems (forms, calendar, billing, support) so the automation has the right inputs. You can integrate tools and still have broken processes if your definitions and data model are inconsistent.
How do we prevent lead routing from stealing accounts or creating duplicates?
Make dedupe and account matching the first steps in your routing precedence. Route matched leads to the existing account owner or pod, then apply territory and distribution only for net-new accounts. Log routing_reason and routing_version so disputes can be resolved with evidence.
Should lifecycle stage changes be automated or manual?
Automate stage changes when the trigger is objective and verifiable (meeting held, proposal sent, invoice paid). Keep manual or approval-based transitions when judgment is required (qualification, disqualification, complex multi-stakeholder deals). Always record what moved the stage, when, and from which system.
What data hygiene should we automate first?
Start with entry validation (email format, picklists for geo and industry) then add dedupe detection and a quarantine path. Next, implement enrichment with an overwrite policy and timestamps. Finally, add ongoing audits with a score so you can catch drift after imports and integration changes.
How do we keep revenue reporting trustworthy as automation grows?
Lock down the fields that drive revenue dashboards (lifecycle timestamps, owner fields, pipeline stage, attribution fields) with clear writer rules and audit trails. Add monitoring for missing UTMs, stage stagnation, and sudden shifts in source mix. Treat automation edits as releases with tests and post-deploy reconciliation.
Can ThinkBot implement this across HubSpot, Salesforce, and no-code tools like n8n?
Yes. ThinkBot designs the process contracts first (routing precedence, lifecycle definitions, field governance, mapping registry) then implements in the appropriate automation layer. We are active in the n8n community and also support other stacks when they fit your governance and reliability needs.