
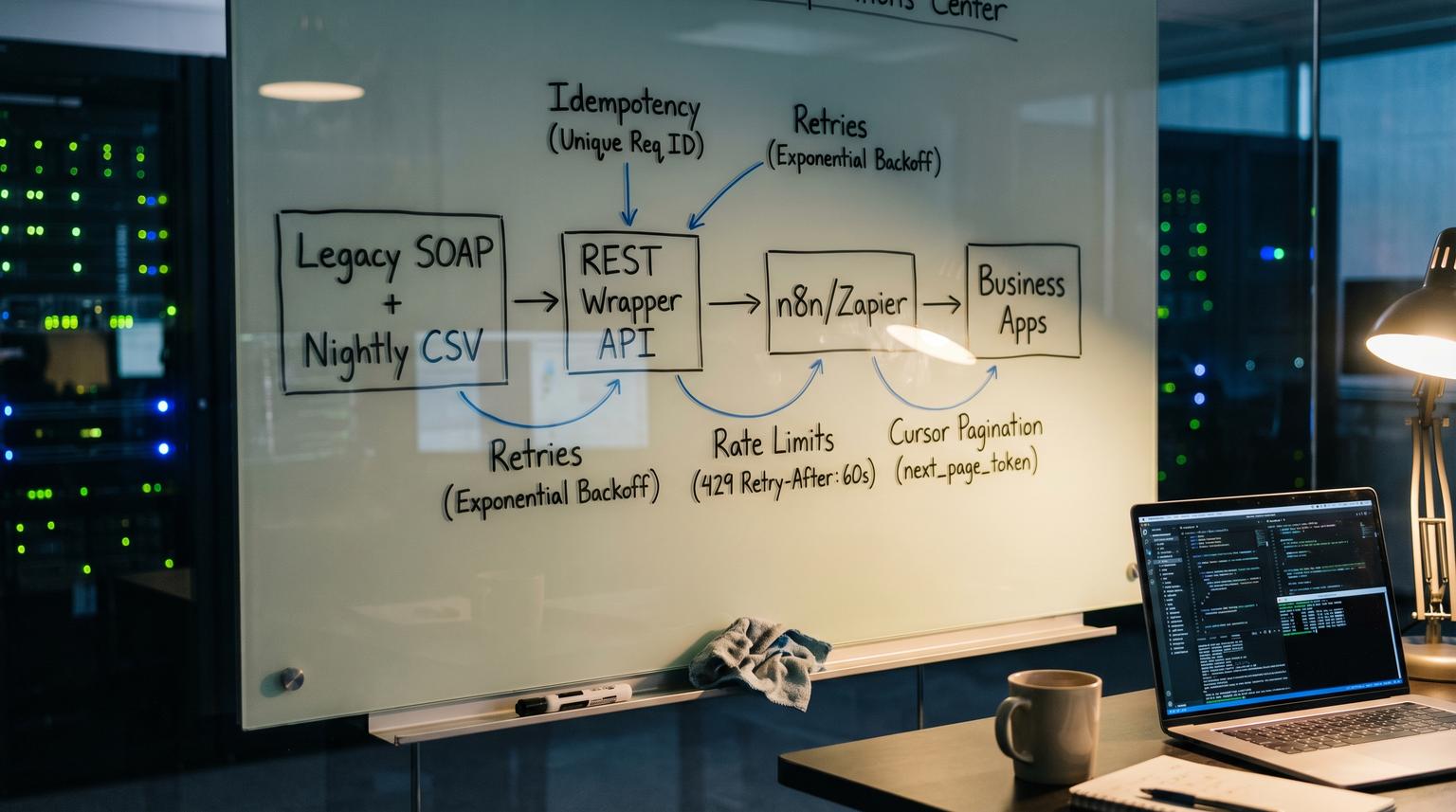
When your core system only exposes SOAP calls or nightly CSV exports, automation ends up fragile: one-off scripts, manual file pulls and duplicate records when a workflow retries. This post shows how to design a thin REST wrapper that turns those legacy interfaces into predictable endpoints for n8n and Zapier. It focuses on custom API development for automation that is safe under retries, rate limits, polling and partial failures.
Quick summary:
- Wrap legacy SOAP and scheduled CSV exports behind a small REST surface that matches real ops tasks: lookups, upserts, status checks and incremental sync.
- Normalize data models so automations never see SOAP operations or CSV column quirks.
- Make writes replay-safe with idempotency keys and dedupe storage so retries do not create duplicates.
- Make reads drainable with cursor pagination, stable sorting and clear throttling signals (429 + Retry-After).
- Ship it like a product: observability, error taxonomy and backfills so workflows stay stable at scale.
Quick start
- Pick 3 to 6 workflow-critical actions (usually: customer lookup, create or update, list recently changed records and fetch status).
- Define normalized objects (Customer, Order, Ticket) and a mapping from SOAP fields and CSV columns into those objects.
- Implement your REST facade with strict contracts: cursor pagination, consistent error responses and idempotent writes.
- Add gateway controls: auth, tenant isolation, throttling and request validation.
- Connect n8n or Zapier using the wrapper endpoints and tune batching, waits and retries using 429 and Retry-After behavior.
A reliable approach is to build a thin REST API that acts as an anti-corruption layer: it translates SOAP XML calls and CSV file semantics into a small set of JSON endpoints with predictable pagination, safe retries and clear rate limiting. Automation tools like n8n and Zapier operate in at-least-once mode under network failures, so the wrapper must support idempotency on writes, incremental reads and token rules that survive long-running workflows.
The integration boundary that keeps legacy quirks contained
Most teams fail here by doing pure protocol translation: SOAP in, JSON out. That makes the first demo work but breaks in production because workflow runners retry and batch in ways your legacy system was never designed to tolerate. The wrapper needs to be a semantic boundary, not just a converter.
The anti-corruption layer pattern is the right mental model: your modern automations speak a clean model and only the wrapper deals with WSDL operations, XML schemas, CSV delimiters and legacy enums. That keeps brittle concepts from leaking into every workflow.
A practical scoping rule
Start with the smallest endpoint set that supports the operations you actually automate today. Expanding later is cheaper than trying to normalize the entire legacy domain up front.
Implementation checklist for the first release
- One canonical identifier per object (internal ID) and one external key strategy (email, account number, SKU) for lookups.
- Stable sorting and cursor pagination for any list endpoint.
- Idempotency required on every write (POST, PUT, PATCH) with deterministic replay behavior. For deeper patterns on reliability, retries, and idempotency in production, use the API Integration Engineering Playbook.
- Rate limiting and backpressure to protect the legacy system.
- Observable errors: correlation IDs, structured error bodies and clear retry guidance.
Minimal endpoint set for n8n and Zapier
The endpoint design should mirror how workflow tools execute: they fetch batches, loop over items and retry failures. Your wrapper should be boring and consistent.

Example endpoint set
- GET /v1/customers (cursor-based list, filter by updated_since)
- GET /v1/customers/{id} (fetch by internal ID)
- GET /v1/customers:lookup (lookup by external keys like email or account_number)
- PUT /v1/customers/{id} (idempotent update)
- POST /v1/customers (idempotent create with Idempotency-Key)
- GET /v1/sync/jobs/{job_id} (status checks for long-running CSV imports)
- POST /v1/sync/imports (trigger ingest of the latest CSV export or upload a file reference)
Example request and response contracts
Create customer (idempotent)
POST /v1/customers
Idempotency-Key: 7b3f2b0a-6b1a-4b1e-9c9a-2f1a3b0f1a11
Authorization: Bearer {access_token}
Content-Type: application/json
{
"external_ref": "ERP-ACCT-10492",
"name": "Northwind Parts",
"email": "[email protected]",
"phone": "+1-555-0100",
"status": "active"
}201 Created
{
"id": "cus_01J4ZKQ9C6S1R9",
"external_ref": "ERP-ACCT-10492",
"name": "Northwind Parts",
"email": "[email protected]",
"status": "active",
"updated_at": "2026-04-11T12:34:56Z"
}
List customers incrementally (cursor)
GET /v1/customers?updated_since=2026-04-01T00:00:00Z&limit=50&cursor=eyJvZmZzZXQiOjUwMH0=200 OK
{
"data": [ {"id":"cus_...","updated_at":"..."} ],
"next_cursor": "eyJvZmZzZXQiOjU1MH0=",
"has_more": true
}
These choices are shaped by how n8n handles throttling and retries and how it benefits from predictable pagination primitives (see n8n rate limit handling). For Zapier polling triggers, incremental reads and tight page sizes help avoid throttles and large result sets (see Zapier throttle behavior). If you want more examples of how these wrapper contracts show up in real automation builds, see API integration solutions with custom n8n workflows and idempotent sync architecture.
Data mapping plan from SOAP and CSV to normalized objects
Your wrapper should expose normalized objects even if the legacy system spreads data across SOAP operations and CSV exports. The goal is that a workflow can treat Customer as a stable JSON document regardless of origin.
Normalized objects
- Customer: identity, contact, status, external references, timestamps
- Order: order header, customer link, totals, fulfillment status, timestamps
- SyncJob: job_id, type, state, started_at, finished_at, counts, last_error
Source fields to normalized mapping example
| Legacy source | Source field | Normalized object.field | Transform rule |
|---|---|---|---|
| SOAP GetAccountResponse | Account.AccountNumber | Customer.external_ref | String as-is |
| SOAP GetAccountResponse | Account.Name | Customer.name | Trim whitespace |
| SOAP GetAccountResponse | Account.EmailAddress | Customer.email | Lowercase, validate format |
| SOAP GetAccountResponse | Account.Phone | Customer.phone | E.164 normalize when possible |
| SOAP GetAccountResponse | Account.StatusCode | Customer.status | Map {"A":"active","I":"inactive","H":"on_hold"} |
| CSV nightly export | last_modified | Customer.updated_at | Parse timezone, convert to ISO-8601 UTC |
| CSV nightly export | account_id | Customer.id (or legacy_id) | Store as legacy_id and mint stable wrapper id |
A real-world ops insight
If your CSV export timestamps only have minute precision, incremental sync can miss updates that happen within the same minute. In that case, use a compound cursor like (last_modified, legacy_id) and always re-read a small overlap window (for example 2 to 5 minutes) then dedupe by legacy_id. This single decision prevents the classic midnight gap where workflows silently stop seeing updates.
Reliability mechanics idempotency retries and throttling
Automation reliability is mostly about how your wrapper behaves when things go wrong: timeouts, partial failures, duplicate events and backpressure. Build these rules into the API so n8n and Zapier do not need bespoke logic in every workflow.

Idempotency strategy that survives at-least-once execution
Require an Idempotency-Key header on all mutating requests. This follows the widely used semantics described in Stripe's idempotency design and it is a perfect match for workflow retries.
- Key scope: (tenant_id, endpoint, idempotency_key)
- Store: request hash, response status, response body, created_at and TTL
- Replay rule: if the same key is seen again with the same request hash, return the stored response without re-calling SOAP or re-importing CSV
- Mismatch rule: if the key is reused with different payload, return 409 Conflict (or 422) with a clear message so the workflow fails loudly instead of corrupting data
Common failure pattern: teams implement idempotency only for POST but not for PUT or PATCH. In practice, workflow builders frequently model upserts as PUT and they will retry those too. Treat every write as retryable.
Retry rules and backoff that protect the legacy system
Your wrapper should be explicit about what is safe to retry and when to slow down.
- Return 429 when the legacy system is at capacity and include Retry-After seconds.
- Return 503 for transient dependency failures (SOAP timeouts, file store issues) and include a message that indicates retryable=true.
- Use exponential backoff with jitter inside the wrapper for SOAP calls but cap the total time to match typical workflow timeouts.
- Expose a correlation_id in every error response so ops can trace one failing run across logs.
Pagination and incremental sync contracts
Cursor-based pagination is more stable than page numbers when the underlying dataset changes. It also helps Zapier polling triggers that must stay under item limits per poll.
- Always sort by a stable monotonic key: updated_at then legacy_id as a tiebreaker.
- Cursor encodes the last seen (updated_at, legacy_id) pair.
- Guarantee: no missing items and no duplicates within the cursor contract even if new records arrive mid-drain.
Token management and auth model that works in workflow runners
Token issues are a major cause of flaky automations. You want a model that is secure but also practical for n8n and Zapier.
Recommended auth approach
- OAuth 2.0 client credentials for server-to-server workflows when possible.
- Fallback: long-lived API keys stored in the workflow tool secret store, protected by per-tenant scopes and IP allowlists.
Token lifecycle rules
- Access tokens short-lived (15 to 60 minutes) and refreshable or re-mintable.
- Wrapper validates token on every request and returns 401 with a consistent error code like auth_invalid_token.
- Support token rotation without downtime: accept the previous key for a short overlap window.
Practical n8n and Zapier compatibility detail
Many workflows run concurrently and token refresh logic can stampede. If you see bursts of refresh calls at the top of the hour, add a small randomized skew to token expiry in your client libraries or prefer client credentials where each workflow can mint independently without a shared refresh token.
Operating the wrapper in production monitoring and failure modes
A wrapper becomes mission-critical once ops teams depend on it. Treat it like a product: versioned contracts, dashboards and safe deploys.
Reference architecture components
A proven pattern is REST facade plus gateway policies plus a transformer service that speaks SOAP and CSV behind the scenes. AWS illustrates this separation with API Gateway fronting a transformation layer (for example Lambda) that converts JSON to SOAP XML and back (SOAP modernization example). You can implement the same shape on other stacks too, the key is the separation of concerns.
Failure modes and mitigations
| Failure mode | What the workflow sees | Mitigation in the wrapper |
|---|---|---|
| SOAP timeout or slow response | Intermittent 500 or long waits | Short dependency timeout, retry with capped backoff, return 503 with retryable=true and correlation_id |
| CSV export delayed or partial | Missing updates during polling | Expose SyncJob status, keep last_successful_export_at, reprocess overlap window and dedupe |
| Workflow retries create duplicates | Double customers or double orders | Idempotency-Key required, dedupe store with request_hash, mismatch returns 409 |
| Legacy rate limits or batch windows | 429s and stalled runs | Gateway throttling, 429 + Retry-After, optional queue for write-behind operations |
| Data model drift in legacy system | Parsing errors after a vendor update | Contract tests against WSDL and CSV schema, versioned mappings and alerts on unknown fields |
A simple rollback plan
- Version your API paths (/v1) and keep backward compatibility for existing workflows.
- Feature-flag new mappings per tenant so you can revert without redeploying.
- Keep replay logs for idempotent requests so you can re-serve responses if a deploy is rolled back mid-run.
If you want a second set of eyes on the endpoint contracts, dedupe design and production guardrails, book a consultation here: schedule time with ThinkBot Agency.
For examples of automation-heavy integration work we ship, you can also review our delivery track record on Upwork.
When a wrapper is not the best fit and alternatives
A thin wrapper is ideal when the legacy system is stable but constrained (SOAP only, CSV only, no webhooks) and you need reliable automation quickly. It is not always the best choice. For a broader view of how custom API integration supports automation across teams and tools, see How Custom API Integration Powers Automation, Workflow Efficiency, and Scalable Growth.
- If you need near real-time eventing and the legacy system cannot provide stable incremental reads, consider a CDC or database-level replication approach instead of polling.
- If the legacy system is being replaced within months, a temporary connector inside n8n may be cheaper, as long as you accept higher operational risk.
- If the legacy API has strict transactional requirements that span multiple operations, a wrapper may need a stateful orchestration layer or a queue which changes scope and cost.
A useful decision rule: if the cost of one failed workflow run is high (lost revenue, compliance risk, customer-facing errors) then invest in the wrapper. If failures are low impact and the integration is short-lived, keep it simpler.
FAQ
Do I need to fully replace SOAP with REST to automate with n8n or Zapier?
No. You can keep SOAP as-is and build a thin REST facade that maps a small set of workflow actions to SOAP operations and returns normalized JSON. The key is not replacing protocols, it is adding predictable behavior like idempotent writes and cursor-based reads.
How do I prevent duplicate records when n8n or Zapier retries a failed step?
Require an Idempotency-Key header on every write endpoint and store a dedupe record per tenant and endpoint. If the same key and payload are replayed, return the original response without re-running the legacy operation. If the key is reused with a different payload, fail with a clear conflict error.
What is the best pagination approach for automation tools?
Use cursor-based pagination with a stable sort, typically updated_at plus a tiebreaker like legacy_id. Return next_cursor and has_more on list endpoints. This prevents missing or duplicating items when records change while a workflow is paging through results.
How should the wrapper handle rate limits so workflows stay stable?
Throttle at the gateway to protect the legacy system then return 429 responses with a Retry-After header when clients should slow down. Keep error bodies consistent and include a correlation_id so operators can trace failures. This lets workflows tune waits and retries instead of guessing.
What token model works best for long-running automations?
OAuth 2.0 client credentials is usually the most reliable for server-to-server workflows because tokens can be minted on demand without shared refresh tokens. If you must use API keys, support key rotation and scope keys per tenant so a single leaked secret cannot access everything.