
Growing companies rarely struggle to start automating, they struggle to keep automations stable as the number of apps, edge cases and stakeholders grows. This guide introduces a reusable Make scenario blueprint for designing and operating scenarios that stay readable, replayable and safe to change across CRM, customer support, operations and marketing. It is written for operators, RevOps and marketing ops leaders and technical founders who want consistent outcomes, fewer silent failures and faster iteration without rebuilding everything each time an app changes.
Key takeaways:
- Design around a canonical payload so routes and mappings survive app changes.
- Separate orchestration from reusable utilities with subscenarios and clear I/O contracts.
- Use routers, iterators and aggregators intentionally, not by habit.
- Build production reliability in from day one: retries, idempotency, logging and alerting.
- Adopt release discipline with blueprint exports, environment separation and ownership.
Quick start
- Write a one-page scenario brief: trigger, success criteria, owners, exceptions and error policy.
- Define a canonical object for the workflow (lead, ticket, invoice, campaign member) and normalize into it early.
- Choose your flow control: router for decisions, iterator for per-item work, aggregator for batching.
- Split reusable capabilities into subscenarios with explicit inputs/outputs.
- Add an idempotency guard before any side effect (create/update/send) and decide replay behavior.
- Configure error handlers and enable incomplete executions for quarantine and retries.
- Implement structured logs with a correlation_id and business identifiers.
- Export a blueprint JSON before and after changes, test with run replay, then promote to production.
A reliable Make.com automation is built like a product: you scope the event and data contract, normalize and validate early, route by business rules, isolate reusable subflows and apply an operations layer for retries, rate limits, logging, alerts and versioned releases. This blueprint lets you reuse the same design across CRM, support, ops and marketing, while keeping scenarios easy to debug and safe to extend as volumes and app complexity increase.
Table of contents
- What a stable Make scenario needs as you scale
- Scope first: the scenario design brief (inputs, outcomes, owners)
- Canonical data modeling in Make: normalize once, map many
- Control flow essentials: routers, iterators and aggregators
- Scenario architecture: single-purpose, orchestration and subscenarios
- Cross-functional pattern library (CRM, support, ops, marketing, reporting)
- Production reliability on Make: error handling, retries, idempotency
- Rate limits and throughput: batching, bulk writes and scheduling
- Observability: structured logs, alerts and incident postmortems
- Governance and release discipline with blueprints
- When to bring in ThinkBot Agency
- FAQ
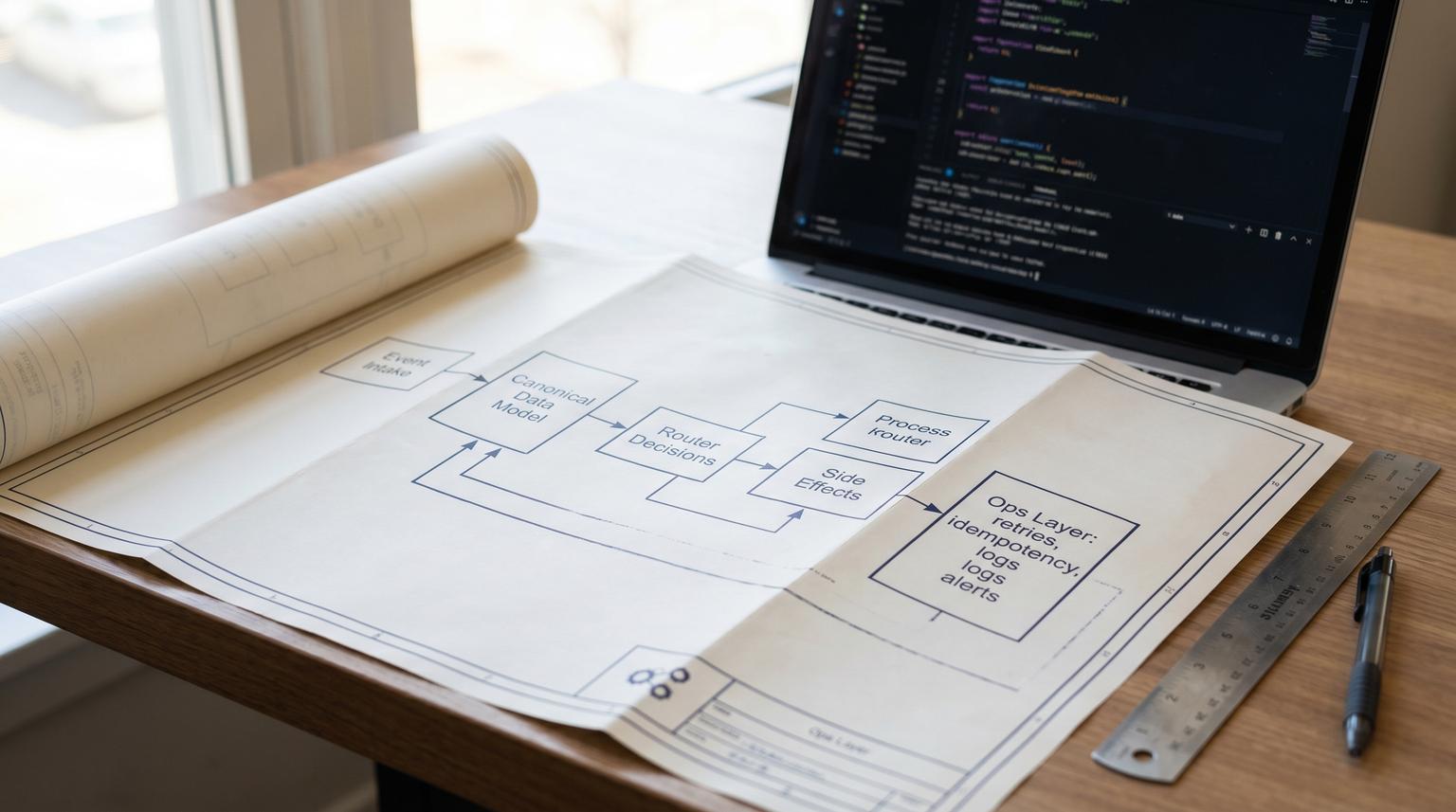
What a stable Make scenario needs as you scale
Most Make.com failures are not caused by Make itself. They come from design drift: fields arrive in a new format, the same event is delivered twice, a webhook spike overwhelms an API or the scenario becomes so long that nobody understands what changed. A stable scenario usually has four layers:
- Event intake: clear triggers, payload schemas and correlation IDs.
- Data contract: normalization into a canonical object before branching.
- Decision and side effects: routers and module chains with safe write patterns.
- Operations layer: error policy, retries, rate limiting, logging, alerting and release discipline.
If you are deciding between tools for complex workflows, this design-first approach also clarifies platform fit. We have a deeper comparison in platform fit and a governance-focused view in governance at scale.
Scope first: the scenario design brief (inputs, outcomes, owners)
Before modules, write a short brief. Make highlights that reliability is decided during scoping, not after the first build, especially around missing fields, exception paths and ownership (this guide).
A one-page brief you can reuse
- Trigger: webhook, scheduled search, app event, manual run.
- Business outcome: what must exist or change in the system of record.
- Required fields: minimum viable payload to proceed.
- System of record: which app is authoritative per object and per field.
- Exceptions: what should be quarantined vs retried vs escalated.
- Owners: business owner, technical owner, on-call channel.
- Success metrics: latency, completion rate, duplicate rate, backlog size.
- Replay policy: what happens if you replay old trigger data.
This brief prevents common rework, like building a two-way sync when you really need a one-way handoff or routing on raw app fields that will change later.
Canonical data modeling in Make: normalize once, map many
As you connect more apps, point-to-point mapping becomes an N-squared problem. A canonical data model (CDM) reduces that by translating sources into a shared representation, then mapping from canonical to each destination (source). In practice, this means your routers, filters and dedupe rules run on canonical fields, not on app-specific payloads.

Mini template: CanonicalContact v1 (copy into your docs)
Use this template when you build lead, contact or requester workflows. It helps you create stable mappings and consistent identifiers.
CanonicalContact v1
- contact_id (string, internal)
- email (string, lowercase, required, unique)
- phone_e164 (string, optional)
- given_name (string, optional)
- family_name (string, optional)
- company_name (string, optional)
- company_domain (string, optional)
- lifecycle_stage (enum: subscriber, lead, mql, sql, customer)
- source_system (enum)
- source_record_id (string)
- updated_at (timestamp)
Mapping rules should live next to the spec: lowercasing emails, normalizing phones and mapping status codes into a stable lifecycle enum. The CDM guidance recommends defining required vs optional fields and uniqueness constraints early so downstream logic stays thin (source).
Dedupe and hygiene as part of the creation path
In RevOps and marketing ops, the most expensive duplicates are the ones created by automations. A practical approach is to combine exact-match and multi-field matching. Email is the highest confidence identifier, phone becomes high confidence after E.164 normalization and name plus company is a medium confidence fallback (source). This directly affects how you build your pre-write search and router conditions.
If your main use case is lead-to-customer, we show an applied version of this model (normalization, dedupe and routing) in lead routing.
Control flow essentials: routers, iterators and aggregators
Make scenarios process data as bundles flowing through module chains (overview). Once you internalize that model, you can choose the right control flow tools deliberately.
How should you branch logic with Routers?
The Router module branches execution into multiple routes controlled by filters (source). Two reliability details matter:
- Routes run sequentially in order, not in parallel. Order is a decision tool, not a visual preference.
- Use a fallback route to catch unmatched cases so you do not silently drop bundles.
In many real scenarios, the first route is a guard clause: invalid payloads, missing required fields, unknown lifecycle_stage, or owner not found. That route should quarantine and alert, not attempt partial writes.
When should you use an Iterator?
Use Iterator when an upstream module outputs an array and you must act per item, for example line items, ticket comments, attachments or multiple recipients (source). A build-time pitfall is missing learned data structures, which can hide fields in the mapping panel. Run the upstream module once to capture the schema before you map heavily (source).
Batching with Aggregators (and where teams get it wrong)
An Aggregator merges multiple bundles into one bundle containing an array, usually after a list/search or an Iterator (source). This becomes your batching boundary. Two guardrails:
- Select the correct source module so you aggregate exactly what you intend.
- If you need fields from modules between the source and aggregator, include them in the aggregator configuration as aggregated fields (source).
Aggregators are a key technique for throughput, especially when paired with bulk write modules, because they reduce API calls and lower the chance of rate limits.
Scenario architecture: single-purpose, orchestration and subscenarios
As workflows grow, the main scaling lever is modularity. Make supports a parent scenario that calls subscenarios using Call a scenario, with Start scenario and Return outputs to define inputs and outputs (source). Treat each subscenario like a tool with a contract.
Synchronous vs asynchronous subscenario calls
- Synchronous: parent waits, uses returned outputs, best for enrichment and validation steps that determine routing.
- Asynchronous: fire-and-forget, best for side effects that should not block, like logging, notifications, or long-running back office work (source).
Comparison table: monolith vs modular scenarios
| Design choice | When it fits | Benefits | Tradeoffs |
|---|---|---|---|
| Single-purpose scenario | One trigger, one outcome, minimal branching | Fast to understand, easy to test, fewer failure surfaces | Can lead to duplicate logic across scenarios |
| Orchestration parent | One intake event needs multiple downstream capabilities | Centralized decisioning, consistent logging, easier change control | Requires disciplined contracts and naming |
| Reusable subscenario utilities | Dedupe, enrichment, upsert, validation, formatting reused often | Single source of truth, smaller blueprints, safer refactors | More moving parts, needs versioning discipline |
| Async subscenario side effects | Non-blocking tasks: audit logs, notifications, delayed jobs | Lower latency for critical path, isolates failures | Eventual consistency, needs its own monitoring |
The table also connects to a practical Make constraint: blueprints must be under 2 MB, which nudges you away from mega-scenarios and toward modular building blocks (source).
Cross-functional pattern library (CRM, support, ops, marketing, reporting)
The goal of a blueprint is reuse across departments. Below are patterns that apply the same principles: canonicalize early, route on stable fields, isolate capabilities, and design for safe replays.
CRM and RevOps: lead -> contact -> deal handoff
- Trigger: form submit, inbound email, ad lead, partner webhook.
- Normalize: CanonicalContact v1, plus CanonicalLead fields (utm_source, campaign, consent flags).
- Dedupe: pre-write search by email, then phone_e164, then fuzzy name+company fallback when email missing (source).
- Route: router routes to upsert contact, create deal, assign owner, or quarantine missing fields.
- Side effects: Slack alert for high intent, task creation, email follow-up.
Implementation note: keep upsert and owner assignment as subscenarios so marketing and sales ingestion share the same rules and so a change in dedupe logic does not require editing every scenario. For a concrete example, see our template approach to building repeatable Make workflows.
Customer support: ticket routing and enrichment
- Trigger: new ticket or new message event.
- Normalize: CanonicalTicket (ticket_id, requester email, product, severity, entitlement, language).
- Enrich: look up customer tier in CRM, pull last invoice status, pull open opportunities.
- Route with priority order: VIP escalation first, billing issues to finance queue, technical issues to engineering queue, fallback to general queue (source).
- Ops layer: structured log for each route decision, plus a quarantine path for missing entitlement.
Reliability tip: ticket systems can send multiple events per conversation. Use an idempotency key based on ticket_id plus event_type plus event_timestamp bucket to avoid duplicate internal notes or duplicate Slack pings.
Back office ops: approvals -> accounting write
Back office scenarios fail most often because they combine human approvals with accounting writes and a retry can create duplicate bills. Use a two-step design:
- Scenario A: intake purchase request, route approvals, write an audit record, return an approved payload.
- Scenario B: accounting writer, idempotent upsert into the accounting system and emit a receipt log.
This pattern is common for Teams approvals and QuickBooks bill creation, we show a practical approach in approval routing. For reconciliation pipelines, see reconciliation automation.
Marketing ops: list syncs and lifecycle updates
- Trigger: form submit, webinar registration, email click, or scheduled cohort sync.
- Normalize: canonical contact plus consent and attribution fields.
- Field ownership: define one-way vs two-way per field to prevent systems overwriting each other (a frequent hygiene issue in CRMs) (source).
- Batch: use iterator -> transform -> aggregator -> bulk upsert when the destination supports batch APIs (source).
If you are not sure whether Make or Zapier is better for multi-app marketing flows, use our scalable workflows comparison as a decision lens.
Reporting pipelines: operational dashboards that do not lie
Reporting automations are where small data model decisions pay off. A reliable reporting scenario should:
- Read from systems of record, not from intermediate tools.
- Normalize into canonical objects before writing to a warehouse, sheet, or BI staging table.
- Log watermark state (time window, cursor, last_id) and batch size per run.
- Use retry-safe writes (upsert by canonical primary key) so replays do not duplicate rows.
Production reliability on Make: error handling, retries, idempotency
Once a scenario touches revenue or customer experience, treat it like production software. Make provides error handling routes with directives like Ignore, Resume, Commit, Rollback and Break (source). Attach error handlers to the modules that produce side effects, not only at the end.

Design an error policy per module type
- Transient errors (rate limit, timeouts, connection errors): retry automatically via incomplete executions, and do not alert until a threshold.
- Data errors (missing required fields, schema mismatch): quarantine and alert, do not retry blindly.
- Authorization errors (expired tokens, revoked app access): alert immediately, expect manual intervention.
Make can store incomplete executions so you can investigate and later complete runs. This is effectively a built-in quarantine mechanism, but it interacts with settings like sequential processing and data loss behavior, so set it intentionally (source).
Retries and backoff: plan for overlap
Make automatically retries incomplete executions created by RateLimitError, ConnectionError and ModuleTimeoutError, using a backoff schedule. Retried runs restart from the module that caused the error and only a limited number of retries run in parallel per scenario (source). Operationally, that means you must assume a burst of retries after an outage and design side effects to be safe when re-executed.
Replay-safe automation with idempotency
Scenario run replay injects historical trigger data into the current scenario version, re-running downstream modules (source). That is powerful for debugging and backfills, but dangerous without idempotency. Practical patterns:
- Idempotency key: store processed event IDs (or a hash of business identifiers) in a datastore, table, or your DB.
- Upsert: prefer create-or-update operations keyed by canonical identifiers (email, external_id, invoice_id).
- Replay mode: add a variable or route flag that disables notification side effects while you backfill, then re-enable after verification.
Rate limits and throughput: batching, bulk writes and scheduling
Rate limits are a normal part of multi-app automation. Make defines RateLimitError as exceeding an app quota, often aligned with HTTP 429, but providers vary (source). Your blueprint should include a throughput strategy, not just error handling.
Instant triggers: use scenario-level rate limiting first
For webhook-driven scenarios, set the maximum runs per minute so spikes are queued and processed gradually. Make notes that this distributes bursts evenly and missed executions are reprocessed automatically (source). This is usually better than adding Sleep modules everywhere.
Scheduled pulls: limit per run and batch writes
For scheduled scenarios, reduce how much you process per run and increase the schedule interval if needed. The Make guidance suggests limiting records per run (for example, keep it small enough to reduce repeated 429 errors) and using bulk action modules and aggregators to reduce per-record calls (source).
Batch boundary checklist (use before you ship)
- Log batch size and a watermark (last_updated_at, cursor, last_id).
- Use iterator for per-record transforms, then aggregator for bulk writes.
- Group-by when the destination requires partitioning (account, region, workspace).
- Ensure the aggregator includes all fields required downstream, not just the final object.
- Make writes idempotent at the batch level (dedupe keys, upserts).
- Expect retries to re-run the batch. Do not rely on "already ran" assumptions.
- Route partial failures to quarantine rather than retrying the entire batch blindly.
- Document the batch boundary in scenario notes so future edits do not break it.
Observability: structured logs, alerts and incident postmortems
Most teams do not need full APM to operate Make scenarios reliably, but they do need consistent run context. Structured logging is the difference between guessing and querying. Google Cloud describes structured logs as JSON payloads that are indexable and queryable by fields rather than just text (source). You can apply the same idea even if your sink is a database, sheet, or ticketing system.
What to log for every run
- scenario name and version label
- run_id (Make execution identifier) and correlation_id (event id)
- business identifiers: lead_id, deal_id, ticket_id, invoice_id
- stage: normalize, dedupe, route, write, notify
- outcome: ok, quarantined, retried, failed
- error category: mapping, auth, rate_limit, timeout, validation
Even if you only start with a simple log table, you can build dashboards that answer: Which route is most common, which error category is rising, and which business entities were impacted.
Operate automations like incidents, not mysteries
When an automation causes missed follow-ups or duplicated bills, run a lightweight postmortem. Atlassian recommends consistent templates and a blameless, action-oriented review so you can prevent repeats (source). For Make, your corrective actions often map directly to scenario changes: add a validation router, add structured logs, tighten idempotency or set scenario rate limits.
Governance and release discipline with blueprints
Make blueprints let you export a scenario as JSON including modules, settings and mapped values. This is your release artifact and your rollback plan (source). Two important operational notes from Make:
- Importing a blueprint is safest into a new scenario. Importing while editing another unsaved scenario can discard changes.
- Blueprints must be under 2 MB, another reason to modularize and use subscenarios (source).
Release checklist for Make scenario changes
Use this checklist when you ship changes to a live workflow that touches customers, revenue or accounting.
- Export the current live scenario blueprint JSON and store it with a date and scenario name.
- Write a short change note: why, expected outcome, and rollback trigger.
- Clone into a draft/new scenario from the exported blueprint, avoid editing live under pressure.
- Reconnect and verify all connections after import (OAuth, API keys, service accounts).
- Run "Run once" tests with representative payloads and at least one edge case.
- Validate router filters and route order, confirm fallback behavior.
- Verify idempotency guard behavior, especially for replay and retry paths.
- Check scenario settings: incomplete executions, sequential processing, consecutive error disable threshold.
- Activate schedule only after tests pass and monitoring is in place.
- Keep the exported blueprint available for rollback, and document the deployed version label.
Modular governance also includes credential management (who owns connections), environment separation (dev vs prod accounts or at minimum separate scenarios) and scenario documentation (data contract, owners, runbook). As your library grows, this is what keeps handoffs clean.
When to bring in ThinkBot Agency
If you have 10+ scenarios across CRM, support and finance, the fastest path to stability is usually not rewriting everything. It is standardizing your blueprint: canonical payloads, subscenario utilities, an error policy, logging and release discipline. ThinkBot Agency builds and refactors Make.com automations with a production mindset, including custom API connections and AI-driven enrichment where it fits.
If you want a second set of eyes on your highest-risk scenarios, book a working session here: book a consultation.
For examples of how we structure real-world builds, you can also browse our recent work.
FAQ
What is a Make scenario blueprint?
In Make.com, a blueprint is an exported JSON representation of a scenario that includes modules, settings and mapped values. Teams use it for backup, sharing, templating and rollback, and it is a practical release artifact when you change production workflows.
How do I keep Make scenarios maintainable as they grow?
Normalize into a canonical object early, route on canonical fields, keep each route single-purpose, split reusable logic into subscenarios with explicit inputs/outputs and adopt release discipline with blueprint exports, testing and clear ownership.
How do I prevent duplicates when Make retries or I replay runs?
Use idempotency keys, upserts and a processed-events store before any side effect. Treat run replay as a remediation tool that re-executes downstream modules, so add a replay-safe mode that can temporarily disable notifications or other duplicate-prone actions.
What is the best way to handle rate limits in Make.com?
For webhooks, set scenario-level maximum runs per minute to smooth spikes. For scheduled scenarios, reduce records per run, batch with aggregators and use bulk modules. Enable incomplete executions so transient errors back off and retry automatically.
Can ThinkBot Agency review and refactor existing Make scenarios?
Yes. We typically start by mapping your scenario inventory, identifying high-risk flows (money movement, customer comms, CRM writes), then refactor toward canonical payloads, subscenario utilities, idempotency, structured logging and blueprint-based release workflows.