
Customer support teams usually do not fail because they lack effort. They fail because the system around them is inconsistent: messages arrive across channels, context is missing, priorities are unclear, tickets bounce between people and SLAs quietly drift. This playbook shows how to implement support ticket automation as an operating system, not a pile of rules. It is for ops leaders and technical teams who want faster response times, more consistent quality and a safer way to use AI without losing empathy.
You will learn a repeatable framework for omnichannel intake (email, chat, forms), standardized triage (tagging, categorization, priority policies), routing patterns (teams, specialists, load balancing), SLA timers and escalations, knowledge workflows that turn resolved tickets into reusable help content and the human-in-the-loop handoff moments that keep automation reliable as products change.
At a glance:
- Design intake so every request becomes a structured case with identity, context and a clean audit trail.
- Separate prediction (AI signals) from policy (your deterministic rules) to keep decisions explainable.
- Build routing with timeouts and fallbacks so tickets never deadlock or disappear in a queue.
- Run SLAs like scheduled jobs with idempotent alerts and clear escalation ownership.
- Close the loop by converting solved tickets into searchable knowledge and guided self-serve.
- Define human handoff checkpoints, QA scorecards and monitoring so quality stays high at scale.
Quick start
- Pick a system of record for customer identity (CRM ID, verified email, phone) and define merge rules for duplicates.
- Standardize your ticket taxonomy: categories, subcategories, routing tags, priority tiers and required fields.
- Implement an intake pipeline that normalizes all channels into one schema, then enriches with customer tier, plan, region and recent orders.
- Add triage automation that outputs structured fields (not free text), plus a confidence gate and a human review queue.
- Configure routing with specialist-first logic, plus timeouts, overflow queues and after-hours behavior.
- Implement SLA timers with escalation tags to avoid repeated hourly alerts and build an exception path for incidents.
- Create a ticket-to-knowledge workflow: link or draft an article on resolution, route drafts for review, publish and measure reuse.
- Set up monitoring for automation health (ingest gaps, error bursts, latency) and support outcomes (backlog age, SLA risk, repeat contact).
Automate customer support by treating every request as a structured workflow: unify intake across channels, enrich with identity and context, apply consistent triage rules, route work with safe fallbacks, enforce SLAs with timers and escalations, then convert resolutions into knowledge that reduces future ticket volume. The quality lever is not only AI accuracy, it is governance: clear policies, human handoff checkpoints, QA loops and monitoring so automations keep working as volumes, products and teams change.
Table of contents
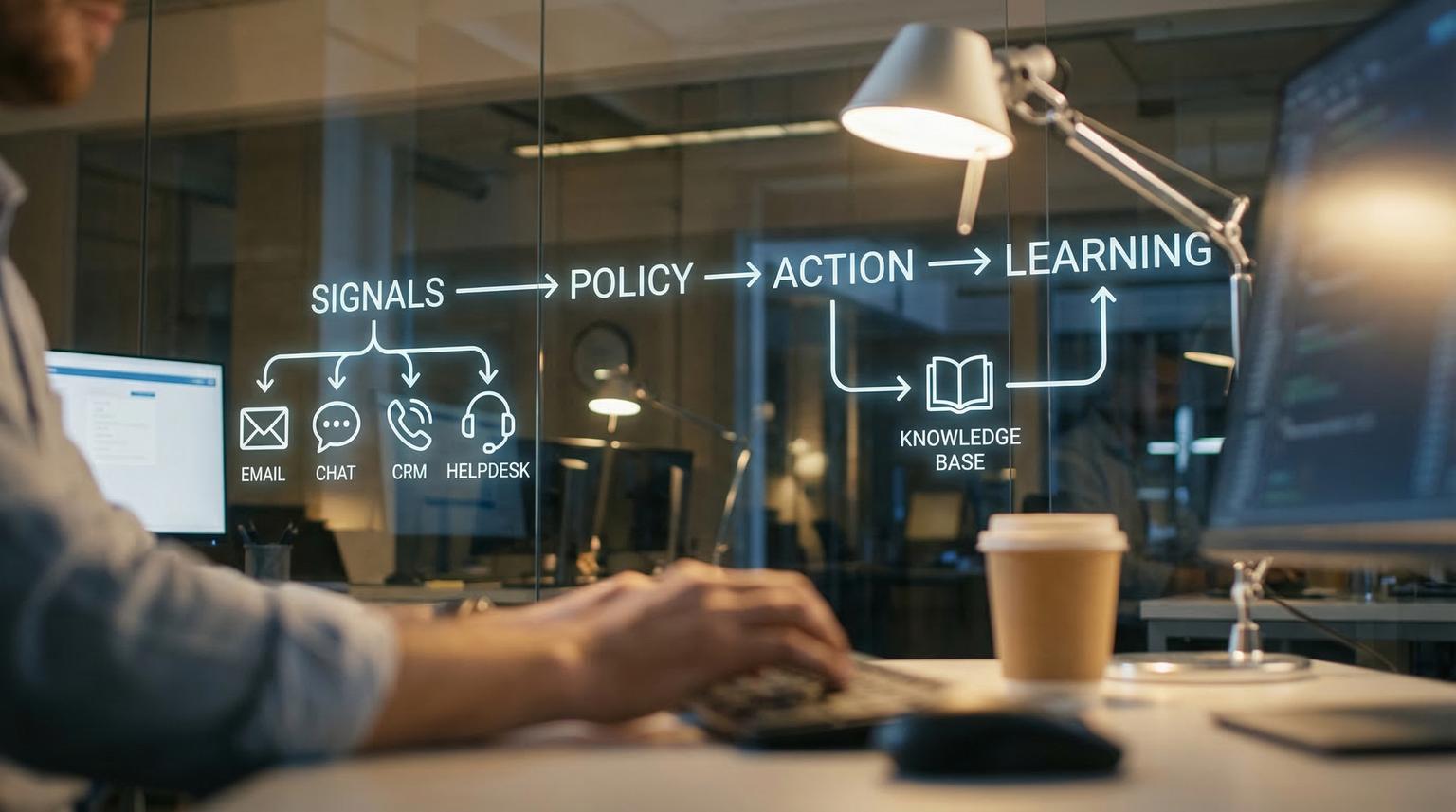
- The automation framework: signals -> policy -> action -> learning
- Intake design: omnichannel normalization and identity resolution
- Triage that scales: taxonomy, AI signals and deterministic priority rules
- Example triage output schema (copy/paste template)
- Routing patterns for teams, specialists and overflow
- SLA timers and escalations without noisy alerts
- Knowledge workflows: turn tickets into reusable help content
- Human-in-the-loop handoff and escalation architecture
- QA loops and content governance (macros, tone, coaching)
- Reliability and observability for support automations
- Implementation checklist for Support Ops and Engineering
- FAQ
The automation framework: signals -> policy -> action -> learning
Most support automation breaks when teams jump straight to tools. A more reliable approach is a closed-loop system with four layers:
- Signals: structured data extracted from messages (language, intent, sentiment, entities like order ID), plus business context (customer tier, incident status).
- Policy: deterministic rules that decide priority, routing, SLA schedules and when to require a human.
- Action: updates in the helpdesk, CRM and messaging systems (tags, fields, assignments, notifications).
- Learning: QA audits, escalation analysis and knowledge reuse metrics that feed improvements back into taxonomy, rules and content.
If you are building this in n8n, ThinkBot has a deep implementation guide on routing-safe triage patterns, including confidence thresholds and CRM syncing.
Intake design: omnichannel normalization and identity resolution
Intake is where quality is won or lost. Your goal is to make email, chat and forms look identical to downstream logic. That means each inbound message becomes a single normalized record with:
- Customer identity (stable key and aliases)
- Channel metadata (email, web chat, social)
- Conversation context (last messages, attachments, timestamps)
- Business context (account tier, plan, region, order history, product version)
- Compliance flags (PII present, legal keywords, refund dispute)
Omnichannel creates duplicates. The same person can show up as separate users across channels, fragmenting history. In Zendesk, you can merge app users via API to consolidate identity and conversation history, but it should be treated like a data migration event with auditing and safeguards, as described in docs. Operationally, you should also account for helpdesk constraints, such as only merging end-user accounts and merge eligibility rules, as noted in Zendesk guidance.
Implementation pattern that works well:
- Resolve identity first, then run triage and routing. If you classify before merging, you often miss VIP status, active incidents and past interactions.
- Use a confidence-based merge strategy. High-confidence matches (same CRM ID) can merge automatically; low-confidence matches route to a review queue.
- Record merge events and show them to agents (who merged, when, why) to avoid confusion during escalations.
If you are also using AI chat experiences, align intake identity with your bot strategy. Our guide on chatbot implementation covers integration and data hygiene considerations that directly affect handoff quality.
Triage that scales: taxonomy, AI signals and deterministic priority rules
Triage is not just categorization. It is the combination of (1) extracting structured fields and (2) applying your policy to produce consistent actions. A practical way to implement this is to separate model predictions from business rules, as recommended in Zendesk triage guidance and reinforced by the idea that prompts should output exact fields that drive routing, not vague analysis, as described in this guide.
Step 1: Standardize your taxonomy
Create a taxonomy that maps cleanly to queues and knowledge. Keep it stable enough for reporting and automation, but flexible enough for product changes.
- Category: billing, technical, account, bug, how-to, feedback
- Subcategory: product-specific breakdown (login, invoice, refund, integrations, deliverability)
- Routing tags: queue__billing, queue__l2_integrations, queue__enterprise
- Priority: P1 to P4 or critical/high/normal/low
- Risk tier: informational, transactional, financial, legal/compliance
Step 2: Extract signals and entities
Signals that often help triage:
- Language, intent and sentiment
- Named entities like order ID, subscription plan, product name, region and version
- Duplicate suspicion and incident correlation
Sentiment can guide priority and specialist assignment, but it should be one input among others. Using sentiment trends for routing and monitoring is discussed in this overview.
For duplicates during incidents, semantic similarity alone is not enough. Adding incident metadata and system-side signals can dramatically improve grouping, as shown by incident-aware aggregation research in this paper. Even if you are not a cloud provider, you can apply the same idea by using status page events, outage windows, product telemetry or release flags as non-text features.
Step 3: Apply deterministic policy
Once you have extracted structured signals, apply your policy in code or rules so it is consistent and auditable. Example policy logic:
- If customer tier is enterprise and intent is outage, set urgency to critical regardless of sentiment.
- If category is billing and sentiment is negative, route to billing specialists trained for de-escalation.
- If duplicate suspected and there is an active incident, attach to the incident master ticket and send the incident update macro.
- If confidence is low or risk tier is financial/legal, require human review before any automated action.
For a full end-to-end example that includes CRM upsert and interaction logging, see our n8n automation blueprint for safe escalation.
Example triage output schema (copy/paste template)
Use this template when you want AI to produce helpdesk-ready fields. It reduces ambiguity and makes routing rules deterministic. It is adapted from a practical triage pattern that recommends structured outputs and explicit review reasons in this guide.
{
"language": "en",
"category": "billing|technical|account|bug|how_to|other",
"subcategory": "...",
"urgency": "low|normal|high|critical",
"sentiment": "positive|neutral|negative",
"routing_tag": "queue__billing",
"duplicate_suspected": false,
"incident_id": "...",
"entities": {
"order_id": "...",
"plan_tier": "...",
"product": "...",
"region": "...",
"version": "..."
},
"needs_human_review": true,
"review_reason": "vip_account|legal|low_confidence|policy_exception|refund_exception|duplicate_suspected"
}
Implementation tip: store the raw model output plus the final policy decision (priority, queue, SLA schedule) so you can audit drift and improve rules without guessing.

Routing patterns for teams, specialists and overflow
Routing is where a good taxonomy becomes operational throughput. The best routing designs are layered and include safety valves.
Pattern 1: Queue taxonomy + routing profiles
A robust mental model is: queues are work buckets and routing profiles define which agents can receive which buckets, plus their priority and delay ordering. This setup sequence is described clearly in AWS guidance and the principles transfer well to most helpdesks.
- Queues by function: billing, technical L1, technical L2, onboarding, cancellations
- Queues by customer tier: enterprise, standard
- Queues by language or region: ES, EU timezones
- Queues by channel: chat vs email (different response expectations)
Pattern 2: Specialist-first then overflow
Use priority plus delay to implement: specialist first, then overflow to trained generalists if it is aging. This is how you keep SLAs during peak load without permanently diluting quality.
Pattern 3: Skills-based routing with timeouts
Skills are powerful but they can create deadlocks. A documented failure mode in omnichannel routing is that tickets can get stuck indefinitely when required skills have no matching agent coverage. A practical mitigation is to configure a skills timeout and a fallback route, as described in Zendesk routing guidance.
Recommended guardrails:
- Always define a timeout for skills-based constraints.
- Define a fallback queue that can at least acknowledge and gather missing info.
- Review skill taxonomy monthly. Too many granular skills usually increases queue aging.
- Add after-hours routes (on-call or deferred with explicit expectations) to prevent overnight breaches.
SLA timers and escalations without noisy alerts
SLAs fail quietly when risk is invisible until the breach is recorded. Build SLA automation that surfaces risk early and creates trackable work items, a key point in this overview.
How to implement SLA escalations in systems with hourly automations
If you use Zendesk-style time-based automations, remember they run hourly, thresholds are whole numbers and conditions like breach time remaining are automation-only. You also need an idempotency mechanism (usually tags) to prevent repeated alerts, as detailed in this guide.
Operational template (conceptual):
- At 4 hours to breach -> notify queue lead, add tag sla_warned_4h
- At 2 hours to breach -> notify on-call, add tag sla_warned_2h
- At breach -> page escalation owner, add tag sla_breached
Design details that prevent chaos:
- Ownership map: each queue has an escalation owner and a backup.
- After-hours schedule: ensure ticket schedules match your business hours and brand/region rules so timers behave predictably.
- Exception handling: incidents may require SLA pauses or a separate incident SLA policy so you do not punish agents for systemic outages.

Knowledge workflows: turn tickets into reusable help content
If automation only speeds up replies, it plateaus. The real compounding benefit comes from converting solved work into reusable knowledge that reduces future volume. Knowledge-Centered Service (KCS) formalizes this by embedding knowledge capture directly into the support workflow, as described in the KCS guide and summarized in this overview.
Ticket -> knowledge loop (practical workflow)
- Agent searches knowledge before responding.
- If an article exists, link it to the ticket and improve it if it is incomplete.
- If no article exists, draft one during resolution using a standard template.
- Route the draft to the right review lane (peer, SME, compliance) based on risk tier.
- Publish, then measure reuse (article links, deflection, repeat contact).
This is also where AI can help safely: suggest relevant articles, propose titles and structure drafts, but keep publishing rights governed. If you are building automated deflection and handoff in a bot, align this with your approved knowledge base approach from our post on knowledge base guardrails.
Human-in-the-loop handoff and escalation architecture
Human-in-the-loop is not a fallback. It is architecture. Designing collaboration checkpoints between AI and humans is the core of safe automation, as argued in this essay. Customers judge automation by what happens when it fails, which is why escalation design should be treated as the product, including clear triggers, ownership and context transfer, as laid out in this practical framework.
Define risk tiers and decision rights
- Tier 1: informational (shipping times, how-to). Automation can respond with approved knowledge.
- Tier 2: low-risk transactional (password reset, address update). Automation can guide, confirm and execute where allowed.
- Tier 3: financial or policy exceptions (refund exceptions, charge disputes). Require approval gates or direct-to-human.
- Tier 4: legal, fraud, compliance. Immediate human escalation, restricted visibility and strict logging.
Minimum handoff payload (so humans do not re-triage)
- Conversation summary (what happened and what was attempted)
- Detected intent/category and confidence
- Sentiment signal and any de-escalation notes
- Customer tier, plan and history highlights (recent orders, open incidents)
- Required next action and recommended owner/queue
Measure handoffs. One metric worth adopting is "escalation accuracy" (how often the system escalates at the right time), which is a useful concept from this source. Track false escalations (unnecessary human work) and missed escalations (automation should have handed off sooner).
QA loops and content governance (macros, tone, coaching)
Automation amplifies both good and bad. QA is how you keep empathy and accuracy as volume grows. A practical QA rubric should evaluate both the "what" (resolution correctness) and the "how" (tone, clarity, empathy), aligning to real customer expectations, as outlined in this guide.
What to audit
- Correct identification and verification steps
- Correct categorization and tags (so reporting and routing are trustworthy)
- Resolution accuracy and policy adherence
- Empathy and de-escalation when sentiment is negative
- Handoff quality (context transferred, no reset)
Macro hygiene and versioning
Macros are production assets. They need naming standards, owners, review cadence and versioning to prevent drift and duplication. Treat macro changes like controlled releases, a set of best practices described in this guide. Automation can suggest the right macro based on tags, but agents should remain accountable for final tone and exceptions.
Reliability and observability for support automations
Support workflows depend on external systems: helpdesk APIs, email providers, chat webhooks, CRMs and LLM endpoints. Production readiness requires monitoring automation health separately from support outcomes.
What to monitor (automation health)
- Ingest gaps: email/chat/form events going silent
- Error bursts: spikes in failed API calls, timeouts, webhook 500s
- Processing latency: time from message received to triage and assignment
- Schema failures: parsing errors after field changes
These dashboard and alert patterns are practical and well described in this guide.
What to monitor (support outcomes)
- First response time by channel and tier
- Backlog age distribution by queue
- SLA risk and breach counts, plus leading indicators
- Repeat contact rate and reopen rate
- Deflection and knowledge reuse (article links per ticket)
Operational excellence: alerts with owners and runbooks
Alerts without an owner are noise. Define a response process: who gets paged, what they do, how incidents are tracked and how fixes are deployed. These operational excellence recommendations map well to automation programs in Microsoft guidance.
Change management essentials
- Version your workflows (even if it is just exporting JSON and tagging releases).
- Use staging for routing and SLA rules where possible.
- Add a kill switch for high-risk automation actions (refunds, account changes).
- Log every automated decision with inputs and outputs for auditability.
- Plan rollback: revert to last known good configuration and route to humans with full context.
Implementation checklist for Support Ops and Engineering
Use this checklist when you are preparing to launch or refactor a customer support automation program. It is designed to prevent the most common failures: missing ownership, inconsistent taxonomy, deadlocked routing and silent SLA breaches.
- Define system-of-record identity keys and rules for duplicate detection and safe merges.
- Normalize intake across channels into one schema (identity, channel, timestamps, attachments, consent flags).
- Standardize taxonomy (categories, subcategories, routing tags, priority levels) and map each to queues and macros.
- Implement triage as structured extraction plus policy application, with confidence thresholds and a review queue.
- Design routing with timeouts, fallbacks and after-hours behavior so tickets cannot stall indefinitely.
- Implement SLA alerts with idempotency tags and clear escalation ownership per queue and tier.
- Define incident workflows: duplicate grouping, customer broadcast updates and SLA exceptions during outages.
- Build the ticket-to-knowledge loop (link or draft article at resolution, review lanes, publish controls).
- Establish QA scorecards and coaching loops that measure empathy, accuracy, policy adherence and handoff quality.
- Set up observability for ingest gaps, error bursts, latency, plus dashboards for outcomes and risk.
- Create change control: owners, review cadence, staging, versioning and rollback runbooks.
- Document human-in-the-loop checkpoints, risk tiers and decision rights for financial, legal and VIP cases.
If you want help implementing this end-to-end in n8n or integrating your helpdesk with CRM, email and internal tools, ThinkBot Agency can design and deploy a production-ready workflow with monitoring, guardrails and handoff UX. You can book a consultation to map your queues, SLAs and knowledge loop into an implementable automation plan.
For examples of what we have delivered across industries, see our portfolio.
FAQ
What is the best first workflow to automate in customer support?
Start with intake normalization and triage tagging because it improves every downstream step. Unify channel inputs, enrich identity and customer tier, then apply consistent categories and priority rules. This gives immediate benefits in reporting, routing and SLA performance without taking risky actions.
How do we keep AI triage from making the wrong call?
Use AI outputs as signals, not decisions. Require structured fields, enforce confidence thresholds and send low-confidence or high-risk tickets to a human review queue. Log model outputs and final policy actions so you can audit errors and tune rules over time.
How should we design SLAs so they do not breach silently?
Implement leading indicators and escalations before the breach. Use idempotent tags so alerts do not spam hourly and define escalation owners per queue and tier. For minute-level precision, consider event-driven scheduling outside the helpdesk instead of relying on hourly checks.
What does a good human handoff include?
A good handoff transfers context, not just the conversation transcript. Include a summary, detected category/intent, confidence, sentiment, key customer details and the recommended next action. Also set a tier-based SLA for the handoff so the customer knows what happens next.
Can ThinkBot integrate our helpdesk with CRM and internal tools?
Yes. ThinkBot builds custom workflows that connect helpdesks, CRMs, email platforms and internal systems via APIs. Typical deliverables include identity resolution, triage enrichment, routing and SLA escalation, knowledge workflows and monitoring so automations stay reliable as you scale.