
When teams scale Zapier automation beyond a few simple Zaps, the biggest reliability break is not triggers or rate limits. It is where you store the canonical record and workflow state. If your CRM, Zapier Tables and Airtable each hold partial truth then multiple Zaps start competing to create and update the same entity. The result is duplicate records, conflicting lifecycle stages, broken handoffs and reporting you can no longer trust.
This article is for Ops and RevOps teams who are building or refactoring production-grade workflows like lead intake, routing, lifecycle changes, task creation and multi-step approvals. You will get a scenario-based decision matrix and concrete guardrails for IDs, deduplication, write ownership and logging so your automations stay stable as volume and teams grow.
Quick summary:
- Pick one canonical system for each entity and for each piece of workflow state or you will get duplicates and drift.
- Use a stable identifier strategy (system IDs plus a consistent dedupe key order) and propagate IDs across apps.
- Define write ownership rules at the field level so only one system is allowed to change lifecycle, approval status and routing decisions.
- Log every create and decision with IDs and timestamps so you can trace issues in minutes not days.
Quick start
- List your core entities (Lead/Contact, Company, Deal, Ticket) and the workflow states you automate (stage, owner, SLA task, approval status).
- For each workflow state, decide where it must live to stay correct under concurrent updates: CRM, Zapier Tables or Airtable.
- Choose your ID strategy: capture system record IDs on create then store and reuse them for all future updates.
- Standardize dedupe rules for every intake: search by primary key then fall back to secondary keys then create only if no match.
- Implement write ownership: one writer per field group plus guardrails (filters, find-or-create, loop prevention and run logging).
The most reliable architecture is the one where the CRM remains the canonical record for people and pipeline while a single system (CRM fields, Zapier Tables or Airtable) is designated as the canonical workflow-state store for the states you automate. You prevent duplicates by using stable IDs and consistent find-then-update-or-create behavior. You prevent drift by assigning write ownership for key fields and logging every decision so conflicting updates are detectable.
Why duplicates and workflow drift show up as you scale
At small scale you can get away with a Zap that simply creates a record. At larger scale, three things change:
- More triggers overlap. Multiple Zaps listen to the same event and each tries to create the same record.
- Retries become common. Timeouts and replays can rerun actions and create a second record if your logic is not idempotent. Zapier calls this out as a common cause of duplicates and recommends using Zap History to pinpoint the exact step that created the duplicate: Zap is creating duplicate data.
- Multiple systems write partial state. Your CRM workflow updates lifecycle stage, a Zap sets stage based on form data and a sales tool also updates the same fields. The record looks like it is changing randomly because it is.
A common failure pattern we see in RevOps is storing workflow state inside Zap logic instead of in a canonical place. Example: one Zap decides “qualified” based on enrichment data and another decides “qualified” based on meeting booked. A month later the criteria diverge and you now have two definitions of “qualified” that fight each other depending on which Zap ran last.
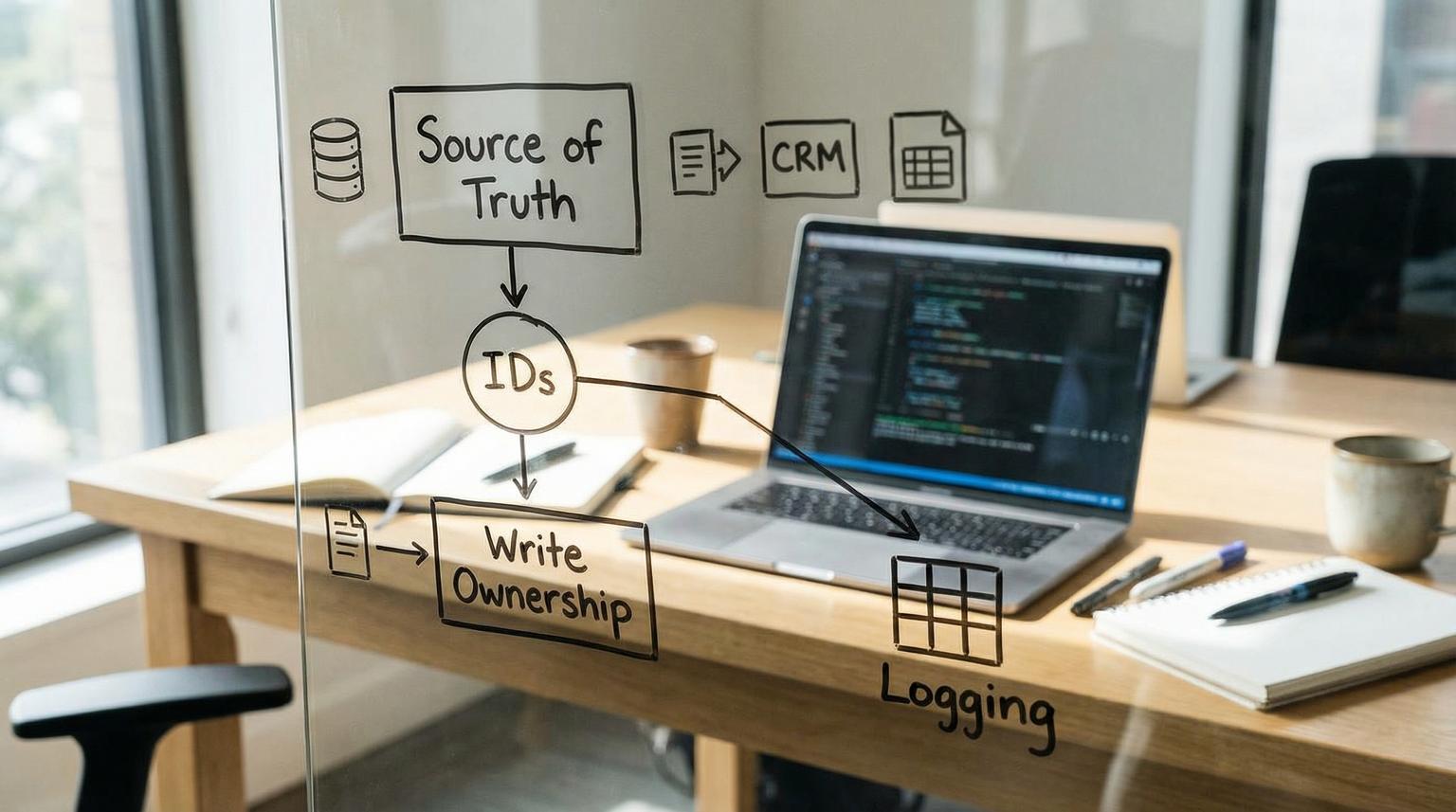
What “source of truth” really means in automation
For scalable workflows, you need two related decisions:
- Canonical record store: where the definitive Contact, Company or Deal record lives.
- Canonical workflow state store: where the definitive state of the workflow lives (routing decision, lifecycle stage, approval status, SLA timestamps and task completion state).
Those can be the same system or different systems. The key is clarity and enforcement. If you do not explicitly assign it, your Zaps will unintentionally create a distributed system where “truth” depends on timing.
One nuance that matters here is how apps behave when you try to create a duplicate. Zapier notes that if an app allows duplicates, Zapier will happily create them. If the app does not allow duplicates, you may get an error. Some apps update existing records and some may silently ignore duplicates which is even worse because the Zap appears successful: How Zapier handles duplicate data. Your architecture should not depend on “hoping” the destination prevents duplicates.
Decision matrix CRM vs Zapier Tables vs Airtable
Use the matrix below to choose the canonical location for workflow state by scenario. The most important columns are write ownership and identifier strategy because they determine whether your system can be made deterministic. If you want a deeper, team-scale approach to governance, monitoring, and incident response, use our Zapier automation blueprint for production-ready team workflows alongside this matrix.
| Scenario | Best canonical record | Best canonical workflow state | Unique ID and matching order | Write ownership rule | Logging and drift detection |
|---|---|---|---|---|---|
| Lead intake from many sources Web forms, inbound emails, partner lists, enrichment tools |
CRM (Contact as system of record) | CRM for lifecycle and owner Optional: Zapier Tables for lightweight intake queue |
1) CRM Record ID after create 2) Before create: work email 3) Secondary: LinkedIn URL 4) Tertiary: email + domain |
Only one workflow creates Contacts. All other Zaps must use find-then-update. CRM owns lifecycle stage. | Zap History plus a dedicated log row per intake event with external source ID, CRM ID and dedupe keys. |
| Lifecycle stage updates MQL to SQL, nurture loops, disqualification reasons |
CRM | CRM (stages should live where reporting lives) | Update by CRM Record ID whenever possible. If using upsert by email, document overwrite risks. | Either CRM workflows OR Zapier changes stage, not both. If Zapier changes stage then CRM automations should read-only those fields. | Write a “stage_change_source” field and store last writer, timestamp and reason. |
| Multi-step approvals Discount approval, legal review, onboarding exceptions |
CRM for customer record Airtable if the approval is a structured workflow with many steps and roles |
Airtable when you need relational approval steps and audit trail Zapier Tables only for simple approve/deny queues |
Airtable Record ID as the approval object key. Store CRM Deal ID inside Airtable and store Airtable Record ID back in CRM. | Approval status is written only by the approval system. Zaps translate status to CRM fields but never “decide” approval in code. | Approval log table with step, approver, time and decision payload. Alert on missing IDs. |
| Task creation and SLA timing Create tasks after lead routing, renewals, follow-ups |
CRM | CRM if tasks are for reps and reporting Zapier Tables if tasks are internal ops queue not visible to sales |
Task object should store CRM Contact or Deal ID. Use a deterministic task key like (deal_id + task_type). | One Zap owns task creation for that task type. Re-runs must update the same task not create a new one. | Log task_key plus resulting task_id and due date. Monitor for duplicates by task_key. |
How to interpret the matrix
- Default to the CRM when the state drives pipeline reporting, forecasting or rep workflows. You want the data to live where dashboards and permissions already exist.
- Use Zapier Tables as a lightweight staging layer when you need a simple queue, a retry buffer or a mapping table. It is great for operational glue but usually not the best long-term store for complex workflow state.
- Use Airtable when the workflow state is a first-class process with steps, approvals, linked records and an audit trail. Airtable IDs make this stable if you propagate them correctly. Airtable explains how to access Record IDs which you should intentionally expose to your automations: Finding Airtable IDs.
Identifier strategy that prevents duplicates in real life
Duplicates happen when your Zaps do not have a deterministic key. Names, company strings and free-text fields are not keys. A practical approach is:
- Always capture the destination system ID on create and store it back in the upstream system that triggered the flow.
- Standardize a dedupe key order so every workflow matches the same way. A common pattern is trigger then search then branch update-or-create. Practitioner playbooks recommend a consistent ordering like email then LinkedIn URL then fallback combinations so new sources do not create shadow records: trigger-search-branch pattern.
- Make retries idempotent by using a deterministic external key. If the same event replays, the workflow should update the same record.

A simple dedupe key order template
Use this as your team standard for Contacts. Adjust to your market and data quality:
- Primary: work email (normalized to lowercase)
- Secondary: LinkedIn profile URL (normalized)
- Tertiary: external_source + external_source_person_id (if you have one)
- Last resort: email + company domain (with caution)
The operational insight: once you have more than two lead sources, the “last resort” rule becomes the main source of duplicates because each source formats names and domains differently. If you must use a fuzzy fallback, isolate it to a single controlled intake Zap and log every match decision for review.
Write ownership rules so workflow state does not drift
Most drift is not caused by a single bad Zap. It is caused by competing writers. Define ownership like you would for code: one system owns a field group and everything else is read-only.
- CRM owns: lifecycle stage, deal stage, pipeline owner, close dates and core reporting fields.
- Automation layer owns: operational routing decisions, enrichment fields and task scheduling logic, but only if those fields are not also being changed by CRM workflows.
- Approval system owns: approval status, approval timestamps, approver identity, exception reasons.
Then implement those rules in Zapier with guardrails:
- Filters to prevent writes when preconditions are not met (for example only set owner if owner is empty).
- One Zap per “writer” per entity type and field group. Prefer consolidating logic with Paths to reduce multi-Zap collisions.
- Loop prevention by using flags like “updated_by_automation” and by scoping triggers to only meaningful changes.
Implementation pattern for the three core scenarios
1) Lead intake and routing
The default shape should be deterministic:
- Trigger from the lead source.
- Normalize identifiers (lowercase email, strip tracking params from URLs).
- Search CRM by primary key (email).
- If not found, search by secondary key (LinkedIn URL or external ID).
- Update if found. Create if not found.
- Write source tagging fields (source, campaign_id, first_touch_timestamp).
- Create routing task using a deterministic task_key.
This is the single best place to eliminate duplicates because every future workflow will build on the same Contact.
2) Lifecycle updates
Keep lifecycle state in one place. If you decide the CRM is canonical then do not mirror lifecycle logic in multiple Zaps. If you need automation-driven changes, use a single Zap that writes stage and writes a reason field plus a timestamp. Also test how your CRM behaves on updates, including whether it overwrites or appends data.
If you are standardizing repeatable builds across departments, see how enterprise teams approach governance and ROI in Zapier automation for enterprises.
If you use HubSpot, their API docs show two important mechanics: updates can be done by record ID or by email and batch updates require record IDs. For upsert, email works but custom ID properties are often safer when you need partial update behavior. See: HubSpot contacts API guide.
PATCH /crm/v3/objects/contacts/{email}?idProperty=email
POST /crm/v3/objects/contacts/batch/update
POST /crm/v3/objects/contacts/batch/upsert

3) Approvals that span apps
If the approval is more than a simple yes/no then treat it as its own object. Airtable often fits because it can model: request, steps, approvers and attached context. The key is to use Airtable Record ID as the deterministic update key and store it back to the CRM Deal or Ticket. Without that loop, Zaps fall back to weak matches and you will eventually approve the wrong record.
Operational guardrails checklist for stable automations
- Entity mapping: For each Zap, document which entity it touches and which system is canonical for that entity and for each workflow state field.
- Stable IDs: On create, store destination record ID back to the source. Never rely on name matching for updates.
- Dedupe order: Use the same primary then secondary then tertiary match keys everywhere.
- Find-then-write: Prefer find-or-create actions when available. If not available, implement explicit search plus branching.
- Write ownership: One owner system per field group. Add filters to avoid overwriting user-entered values.
- Trigger hygiene: Scope triggers to the smallest change set that matters. Avoid “any update” triggers unless you can gate them.
- Retry safety: Assume retries and replays will happen. Use idempotent keys like external_event_id or task_key.
- Collision control: Reduce multiple Zaps using the same trigger. Consolidate where possible using Paths and shared subflows.
- Logging: Store run metadata (timestamp, source event id, matched keys, chosen record id, action result). Use Zap History to trace runs by identifier as Zapier recommends.
When CRM, Zapier Tables or Airtable is not the best fit
Not every workflow belongs in these three options:
- If you need strict transactional guarantees across many writes, you may need a dedicated database plus an integration layer that supports locking and queues. Zapier can still orchestrate but it should not be the transaction coordinator.
- If your team cannot maintain ID discipline (for example they cannot preserve external IDs during imports) then a separate workflow database will become a second source of chaos. In that case simplify and keep more state inside the CRM with fewer writers.
- If approval workflows require complex permissions, SSO policies or custom UI, Airtable may not meet governance needs and a purpose-built approvals tool could be better.
How ThinkBot Agency helps teams scale without data chaos
At ThinkBot Agency we typically start by mapping entities, IDs and write ownership then we refactor Zaps into a smaller set of deterministic workflows with consistent dedupe logic and run logging. This reduces duplicates, improves attribution and stops lifecycle drift without slowing down the business.
If you want the reliability fundamentals (dedupe, error handling, monitoring, and clean sync patterns) in one place, review our Zapier automation best practices.
Book a consultation if you want us to review your current automations and propose a source-of-truth design that can handle higher volume and more apps.
FAQ
Should the CRM always be the source of truth?
For Contacts and Deals, usually yes because reporting, permissions and downstream sales processes live there. But workflow state like multi-step approvals can be more reliable in an external system if it needs an audit trail and structured steps. The key is to keep one canonical place for each state and propagate IDs.
What is the minimum identifier setup to stop duplicates?
You need a consistent dedupe key order (like email then LinkedIn URL) and you need to store the destination record ID after creation then use that ID for all future updates. Without storing IDs, retries and multi-Zap collisions will eventually recreate records.
How do I enforce write ownership in Zapier?
Use filters and conditional logic so Zaps only write fields they own and only when conditions are met. Consolidate competing Zaps that update the same fields and standardize on find-then-update instead of always creating. Also add a “last_updated_by” field or similar to make conflicts visible.
What should I log so drift is detectable?
Log the source event ID, dedupe keys used, the matched record ID, whether the Zap updated or created, the fields changed and a timestamp. With that, you can trace a duplicate or incorrect stage back to the exact run in Zap History and fix the responsible step.